Human-AI Shared Control via Policy Dissection
In many complex tasks, RL-trained policy may not solve the tasks efficiently and correctly. The training process may cost too much time. Policy dissection is a frequency-based method, which can convert RL-trained policy into target-conditioned policy. For this method, human can interacte with AI inorder to get a more good and efficeient result. In this project, we want to explore the human-AI control and implementation of the policy dissection. We will add new action in MetaDrive enviornment.
- Presentation
- Introduction
- Human-AI Shared Control
- Policy Dissection
- PPO Result on MetaDrive
- Policy Dissection Result
- PPO with Policy Dissection vs PPO
- Exploration
- Conclusion
- Future plan
- Installation
- Reference
Presentation
Introduction
This article will refer to the source code .
First of all, we want to explore the relationship between kinematic behavior and the neural activities. In this experiment, we want to figure out the patterns behind some certain behaviors.
Second, we will use the metadrive enviornment to explore how PPO works in that environment. The environment includes single agent enviornment and Multi-Agent Environment and real enviornment.
Third, we want to explore what is policy dissection and implement it into metadrive.
Fourth, we will compare the policy dissection versus the PPO algorithm to explore the performance of policy dissection.
Finally, we will try to figure out whther policy dissection can be used in many real world scenarios for our future research plan.
Human-AI Shared Control
The present human-AI shared chontrol methods can be roughly divided into two categories. The first category is involving training with a human control and testing the trained policy withou the human control [5]. The other is to have human carry out human auxiliary tasks throughout both training and testing. In policy dissestion method, it allows the human cooperate with AI during the testing, but human does not participate in training.
In the test, humans need to trigger some subtle operations when necessary, such as shifting to the left and jumping, to help better complete the task.
Policy Dissection
-
What is the Policy Dissection?
Previous reinforcement learning methods have attempted to design goals-conditioned policies that can achieve human goals, but at the cost of redesigning reward functions and training paradigms. Hence the Policy Dissection, an approach inspired by neuroscience methods based on the primate motor cortex. Using this approach, manually controllable policies can be derived in trained reinforcement learning agents. Experiments show that under the blessing of Policy Dissection, in MetaDrive, it can improve performance and security.
-
Four main steps for Policy Dissection[1]
1. Monitoring Neural Activity and Kinematics: The policy dissection expands the trained policy and records the tracked neural activities and kinematic attributes, such as velocity and yaw. It will recorde the neural activities and kinematic attributes for further anaylsis.
2. Associating Units with Kinematic Attributes: According to the records of neural activities and kinematic attributes, the same kinematic patterns will appear with different frequencies. So for a kinematic patterns, the unit with the smallest frequency discrepancy is the motor primitive.
3. Building Stimulation-evoked Map: Behavior can be described by changing a subset of kinematic attributes, or by activating a corresponding set of motor primitives. These movements are associated with certain behaviors to generate building blocks that include stimulation-evoked map.
4. Steering Agent via Stimulation-evoked Map: Activate the kinematic attribute associated with the motion property and apply its derivative to the agent. The goal is to find features that can be easily scaled up or down kinematic attributes by selecting a unit.
-
Workflow of Policy Dissection

Fig 1. workflow of Policy Dissection [1].
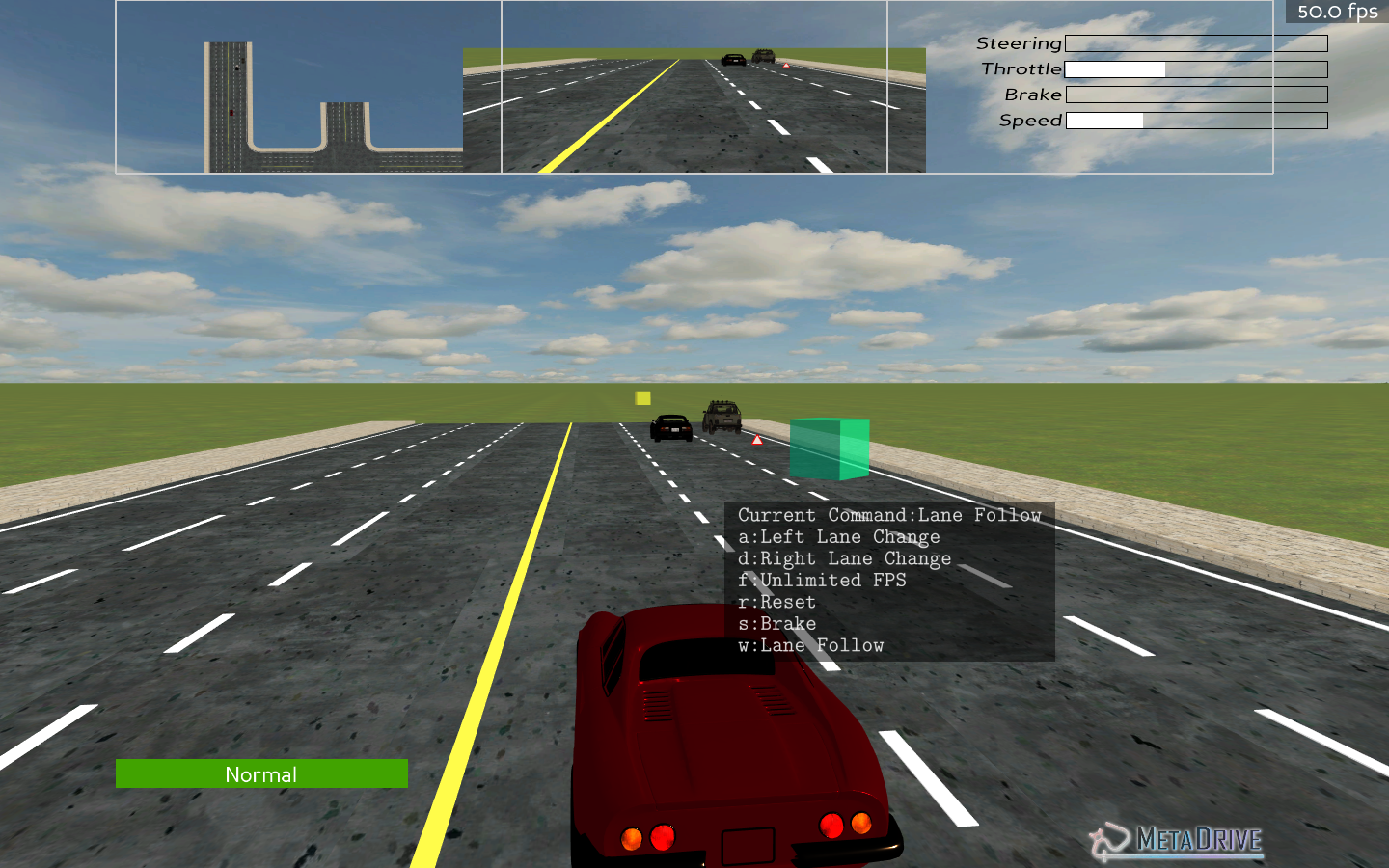
PPO Result on MetaDrive
We try to run MetaDrive with PPO algorithm. We find that in a simple environment (fig 2), our agent can reach destination safely and quickly. But when encountering some complicated situatins (fig 3 and 4), some sign barrels and obstacles are added, and the driving of the agent will have problems. Like situtation in fig 3, the agent directly hit the marked barrels and does not choose to avoid it, resulting in many collisions. Like the situtation in fig 4, the agent slows down slightly when it encounters an obstacle, but it cannot avoid it directly, but looks for the correct direction by collision. These situations may affect the final result, a more or less reduced final reward (you can check the comparsion results in PPO with Policy Dissection vs PPO part).
 Fig 2. Demo 1
Fig 2. Demo 1
 Fig 3. Demo 2
Fig 3. Demo 2
 Fig 4. Demo 3
Fig 4. Demo 3
Here we also procide a video of a car encountering an obstacle while driving. We can clearly see that when the car encounters an obstacle, it will not recognize it, nor will it consciously avoid it, but will directly hit it. This situation greatly affected the final result.

Policy Dissection Result
Here we provide an example of Human-AI shared control through policy dissection method. Through human control, we let the car successfully avoid obstacles and reach the end point.

PPO with Policy Dissection vs PPO
Here we try three road maps:
 Fig 5. road map 1
Fig 5. road map 1
 Fig 6. road map 2
Fig 6. road map 2
 Fig 7. road map 3
Fig 7. road map 3
| Road Map | Algorithm | Episode Reward | Episode Cost | Arriving Destination |
|---|---|---|---|---|
| 1 | PPO with Policy Dissection | 438.050 | 0.0 | True |
| 1 | PPO | 345.505 | 17.0 | True |
| 2 | PPO with Policy Dissection | 341.361 | 0.0 | True |
| 2 | PPO | 297.871 | 8.0 | True |
| 3 | PPO with Policy Dissection | 439.840 | 0.0 | True |
| 3 | PPO | 431.896 | 1.0 | True |
Table 1. All the result on both algorithm
We compare the result of PPO and PPO with policy dissection, we can find that that the overall performance of PPO with policy dissection is much better. First of all, the rewards of PPO with policy dissection are all higher than that of PPO. In the highest case, the reward can be almost 100 higher. The purpose of reinforcement learning is to maximize the total rewards, which means the policy dissection plays a role and improves the performance. Secondly, PPO always has an episode cost, while the episode cost of PPO with policy dissection is always 0. The episode cost is used to detect the safety of driving, and if a crash occurs, the cost will increase by 1. So, this means that PPO has some collisions during the running process, such as colliding with other cars or obstacles, and policy dissection avoids all obstacles very well. At the end, both algorithms can successfully reached the destination. To sum up, the PPO with policy dissection has much better performance than the PPO, which means that policy dissection can help to get better result in test, and can also improve the safety of the entire driving.
Here we also provide the compare video: Watch the video
Exploration
In our daily life, we may encounter a lot of traffic and need to want to change lanes, or want to change lanes when there is a traffic jam. We need to stop first and wait befor changing lanes, just like the situtation presented in fig 8 and 9. In the current actions, there is no action of waiting and changing lanes together, so we try to add this action. This can better simulate some behaviors in real life.
 Fig 8. wait and turn left
Fig 8. wait and turn left
 Fig 9. wait and turn right
Fig 9. wait and turn right
Update and Changes
In metadrive_env.py, we add two new function, bleft and bright, which use to talk the engine what to do in the setup_engine function.
def setup_engine(self):
...
self.engine.accept("g", self.bleft)
self.engine.accept("z", self.bright)
def bleft(self):
self.command = "Brake and Left Lane Change"
def bright(self):
self.command = "Brake and Right Lane Change"
In play_metadrive.py, we add two new action to the conditional control map. “Brake and Left Lane Change” frist slow down the speed and then try to get into left lane. “Brake and Right Lane Change” first slow down the speed and then try to get into right lane.
PPO_EXPERT_CONDITIONAL_CONTROL_MAP = {
"Left Lane Change": {
0: [(1, -8.5)]
},
"Right Lane Change": {
0: [(1, 7)]
},
"Brake": {
0: [(249, -20)]
},
"Brake and Left Lane Change": {
0: [(20, -20), (1, -8.5)]
},
"Brake and Right Lane Change": {
0: [(20, -20), (1, 7)]
}
}
Current Actions we have
| Actions | Command | Setup_engine | | ——- | ——- | ———— | | Forward | Lane Follow | “w” | | Brake | Brake | “s” | | Turn Left | Left Lane Change | “a” | | Turn Right | Right Lane Change | “d” | | Wait and Turn Left | Brake and Left Lane Change | “g” | | Wait and Turn Right | Brake and Right Lane Change | “z” |
Demo
Conclusion
As you can see, using Human AI shared control, enabled by policy dissection, can efficiently solve many hard situations compared to the PPO algorithm.
By increasing the level of traffic density, wait and turn left and wait and turn right will become a safe choice for changing lane. Compared to the directly turn right and turn left, wait and turn left and wait and turn right are less chance to cause collison. In addition, in the real world, in the high way, for safe purpose, we always brake and slow down to turn lane rather than directly turn right or left. For this action improvement, it is more safe and real.
Future plan
Because the human-AI shared control, enabled by policy dissection, can solve a lot of complex situations, we can use the human-AI shared control in the imitation training process. It will become a good demonstration for solving many complex scenarios. We will continue to expore it in the winter break.
Installation
Basic Installation
We completed the basic installation according to the policy dissect’s instructions. It contains some basic packages we need.
Environment Installation
We also installed supported environments for testing the policy dissection method.
Reference
[1] Q. Li, Z. Peng, H. Wu, L. Feng, and B. Zhou. Human-AI shared control via policy dissection. arXiv preprint arXiv:2206.00152, 2022.
[2] D. Bau, J.-Y. Zhu, H. Strobelt, A. Lapedriza, B. Zhou, and A. Torralba. Understanding the role of individual units in a deep neural network. Proceedings of the National Academy of Sciences, 117(48):30071–30078, 2020.
[3] S. Guo, R. Zhang, B. Liu, Y. Zhu, D. Ballard, M. Hayhoe, and P. Stone. Machine versus human attention in deep reinforcement learning tasks. Advances in Neural Information Processing Systems, 34, 2021.
[4] B. Zhou, D. Bau, A. Oliva, and A. Torralba. Interpreting deep visual representations via network dissection. IEEE transactions on pattern analysis and machine intelligence, 41(9):2131–2145, 2018.
[5] R. Zhang, F. Torabi, G. Warnell, and P. Stone. Recent advances in leveraging human guidance for sequential decision-making tasks. Autonomous Agents and Multi-Agent Systems, 35(2):1–39, 2021.
[6] Q. Li, Z. Peng, Z. Xue, Q. Zhang, and B. Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. arXiv preprint arXiv:2109.12674, 2021.
[7] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[8] L. Fridman. Human-centered autonomous vehicle systems: Principles of effective shared autonomy. arXiv preprint arXiv:1810.01835, 2018.