Meta Learning for Reinforcement Learning
For our project, we plan on applying MAML to more difficult RL task distributions than was used in the original MAML paper. Specifically we aim to investigate one and few-shot learning for various locomotion tasks of different creature types.
- Related Papers
- MAML Overview & Approach
- Proposal
- Datasets
- Midterm Update
- Implementation
- Baseline MAML HalfCheetah Task
- GIFs of Adaptation
- MAML Adaptation Delta on Multiple Mujoco Environments
- Discussion & Future Work
- References
Related Papers
-
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks [1] This is the original MAML paper. It applies meta learning to locomotion gym tasks. The method directly optimize for meta parameters that are sensitive to changes in parameter space such that small gradient updates result in large changes in reward/loss in using gradients.
-
Meta-Learning with Implicit Gradients [2]
MAML requires inner loop optimization, necessitating computation of Jacobian which is expensive. This paper proposes using implicit gradients, thereby calculates meta gradients using only final location of inner loop parameters rather than entire path
-
Probabilistic Model-Agnostic Meta-Learning [3]
This paper covers the few shot learning setting, often not enough examples to fully specify task. It uses sample of model from model distribution to adapt to new task.
-
A Survey of Generalisation in Deep Reinforcement Learning [4]
This paper covers current challenges zero shot policy transfer, especially out of distribution generalization where test and train distributions are different
- MuJoCo Open AI Gym Environments [5]
- Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables [6]
MAML Overview & Approach
Model Agnostic Meta Learning proposed by Finn 2017 is a method for learning meta-parameters for fast adaptation to new tasks. For a given task distribution, MAML learns parameters that are sensitive to changes such that small changes in the parameter space result in large changes in the loss function or reward.
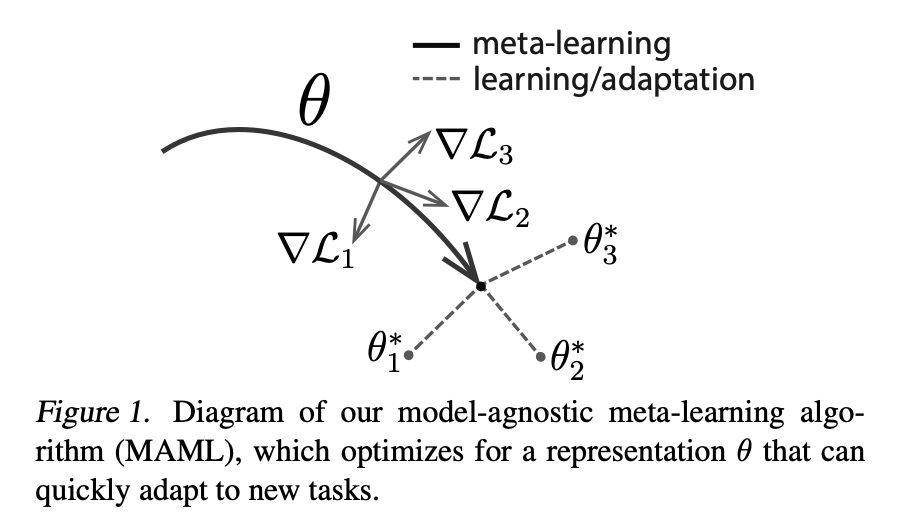
Figure from MAML. [1]. These parameters are found by a nested optimization loop. In the outer loop, a distribution of tasks is sampled. For each task, K gradient steps are taken to optimize parameters (initialized using the meta parameters) for each task with respect to each task’s loss function using gradient descent. The parameters computed to optimize each task are the adapted parameters. In the outer loop, the meta parameters are updated using the gradient of the meta parameters with respect to the sum of the losses of all tasks evaluated using the adapted parameters with gradient descent. Pseudocode for the MAML algorithm is shown below. In the original paper, MAML is shown to achieve state of that art or better performance on few shot learning tasks in vision and RL.

MAML Algorithm [1].
Proposal
For our project, we plan on applying MAML to more difficult RL task distributions than was used in the original MAML paper. The RL task distributions in the original MAML paper were relatively simple: simulated mujoco robots were tasked with moving at a velocity sampled uniformly from a set range of velocities. We propose to use MAML to learn locomotion policies that are agnostic to the body type of the robot. In this case the task distribution would be motion in Ant, Cheetah, Humanoid and other robot body types. This task distribution is considerably more difficult than simply moving at different velocities with the same body. We hypothesize that MAML could learn parameters that are universal to locomotion more generally, including representations of physics dynamics and how leg movement affects robot motion
Datasets
MujuCo is a dataset with locomotion 2-D tasks. It can be accessed through the openAI API and consists of state spacesof body parts and joints with corresponding velocities [5].

MujuCo Dataset: 2D Locomotion [5].
If we have enough time, we will also investigate performance of MAML algorithms on the Meta-World and D4RL environments. Meta-World is a meta reinforcement learning benchmark that includes a diverse set of different robotics arm manipulation tasks.
Midterm Update
We are currently working on building infrastructure to support MAML for RL using Ray RLLib. RLLib has an implementation of MAML already working, which can be used for multiple Mujoco environments. We are also working on creating our own custom environments and policy classes which extend RLLib’s existing classes to support models with image observation spaces. This requires wrapping the env.step functions to render rgb arrays. This will allow us to also experiment with learning directly from pixels which may allow for easier transfer between Mujoco robot bodies, where the legs look similar.
Implementation
Dealing with Varying Observation and Action Space Sizes
Each of the Mujoco environments has different observation space and action space dimensions. To deal with different observation spaces, all observation vectors are padded with zeros to match the observation dimension of the Mujoco environment with the largest observation space dimension. The policy network takes this observation vector and outputs an action with dimension matching the action space dimension of the Mujoco environment with the largest action space. This action is masked to match the valid action space dimension for the currently sampled task. This allows for the same policy network to be used for any task sampled from a distribution of multiple Mujoco environments whose observation and action spaces are all different. A diagram of all the processing steps for producing an action from an observation is shown below.
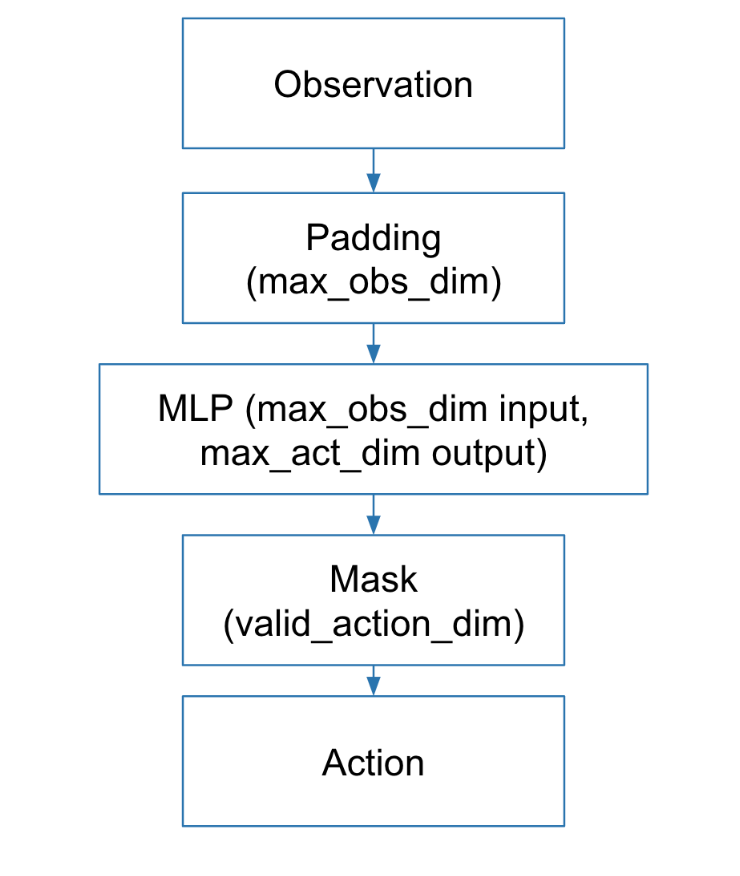
Pipeline for our multiple Mujoco Environments we train MAML on
Our code for MAML with multiple Mujoco environments was implemented using Ray RLLib, which provides useful abstractions for distributed reinforcement learning. Unlike the original MAML implementation, we use Proximal Policy Optimization (PPO) in the inner loop optimization instead of vanilla policy gradient.
Our code can be found here: https://github.com/jamqd/MetaRL-Locomotion/

Baseline MAML HalfCheetah Task
Table of agents.
| Agent | Min Reward over 200 Steps (avg 100 runs) | Max Reward over 200 Steps (avg 100 runs) | Mean Reward over 200 Steps (avg 100 runs) |
|---|---|---|---|
| MAML+PPO (1 step) | 3475.8 | 4638.5 | 4074.6 |
| PPO (1 step) | 1300.9 | 1834.4 | 1541.6 |
| RANDOM | -39.8 | 208.7 | 70.3 |
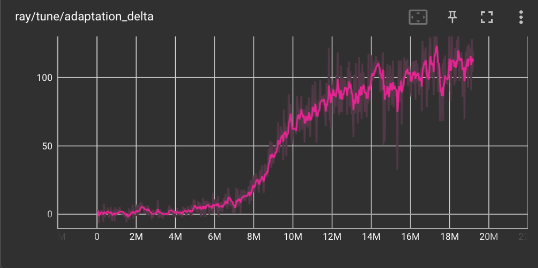
Adaptation Delta of Base HalfCheetah Task
GIFs of Adaptation
- MAML-PPO Agent after 1 Finetune Train
- PPO Agent after 1 Finetune Train
- Random Init
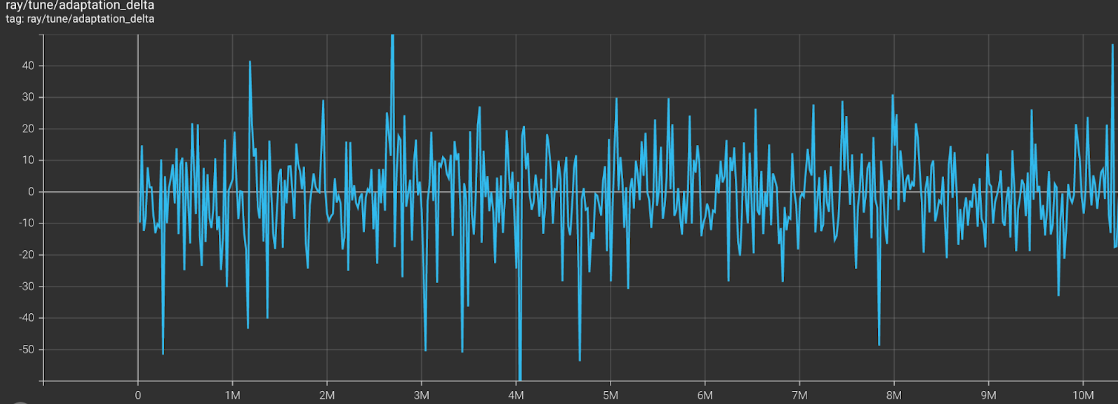
MAML Adaptation Delta on Multiple Mujoco Environments
- Ant and Half-Cheetah
- Walker and Hopper
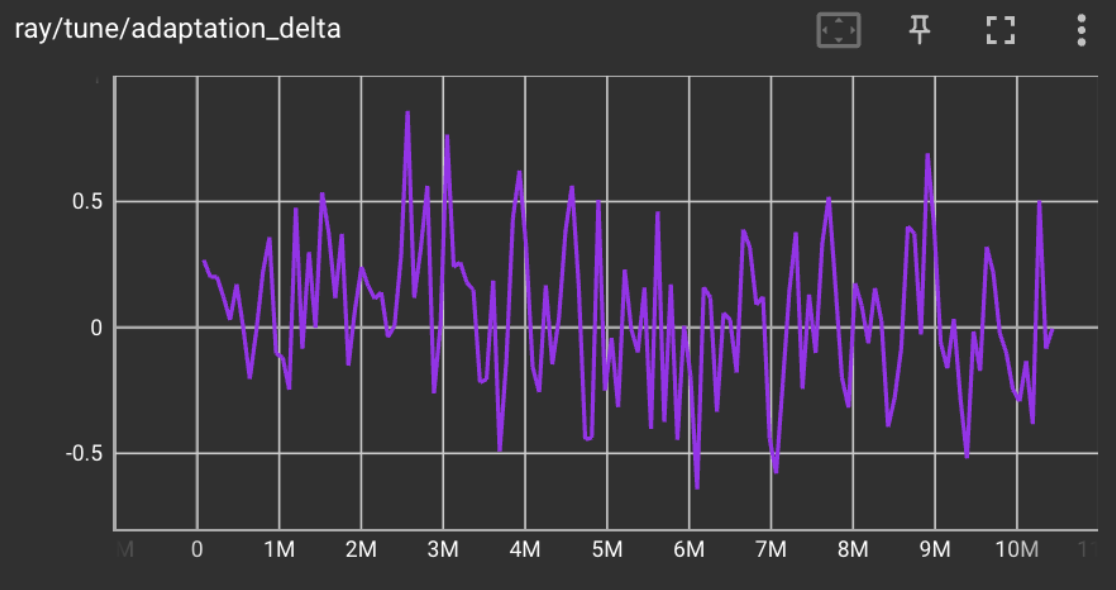
- Ant, Half-Cheetah, Walker, Hopper, Swimmer
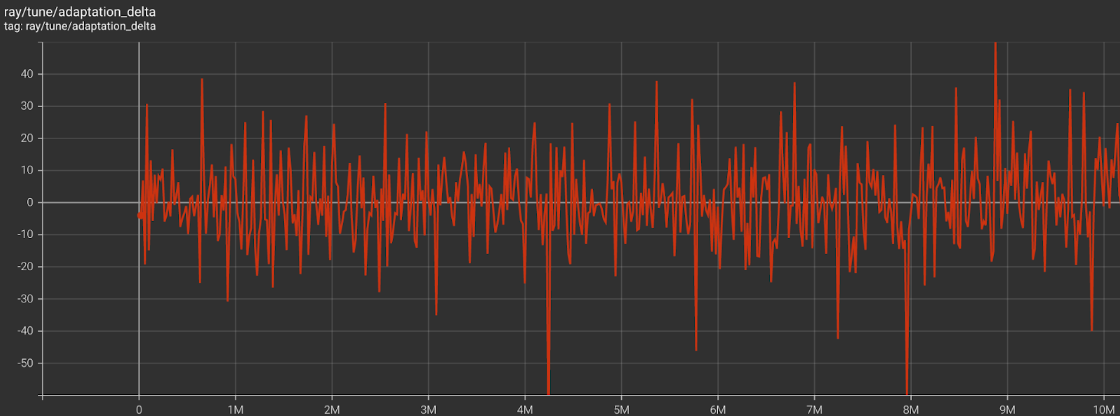
As shown by the graphs above, MAML struggles to meta-learn policies that adapt in few gradient updates when the task distribution is multiple Mujoco Environments. The adaptation delta varies greatly around 0 for multiple combinations of Mujoco environments after 10M training steps.
Discussion & Future Work
While we were able to get MAML to work on the Half-Cheetah Random direction, a tasks that worked in the original MAML paper, the MAML did not successfully learn meta-parameters that quickly adapted with few gradient steps in the experiments we ran with multiple different Mujoco environments.
It may be the case that because the task distribution for multiple Mujoco environments is much more difficult than the task distributions used in the original MAML paper we may need to just train for more iterations or do more hyperparameter tuning to get better adaptation deltas. Future work may involve using more advanced versions of MAML such as Probabilistic MAML or Implicit MAML. It may be the case that even more advanced versions of MAML may fail to meta-learn parameters for multiple Mujoco environments. Thus, it would also be interesting to see how better meta-learning methods such as PEARL, which disentangles learning optimal actions from task-inference. Separating learning from task inference may be especially helpful for our problem setup, since each of the tasks is quite different even though they are all Mujoco locomotion tasks with the goal of moving a simulated robot.
References
[1] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” International conference on machine learning. PMLR, 2017.
[2] Rajeswaran, Aravind, et al. “Meta-learning with implicit gradients.” Advances in neural information processing systems 32 (2019).
[3] Finn, Chelsea, Kelvin Xu, and Sergey Levine. “Probabilistic model-agnostic meta-learning.” Advances in neural information processing systems 31 (2018).
[4] Kirk, Robert, et al. “A survey of generalisation in deep reinforcement learning.” arXiv preprint arXiv:2111.09794 (2021).
[5] Todorov, Emanuel, Tom Erez, and Yuval Tassa. “Mujoco: A physics engine for model-based control.” 2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012.
[6] Yu, Tianhe, et al. “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning.” Conference on robot learning. PMLR, 2020.
[7] Fu, Justin, et al. “D4rl: Datasets for deep data-driven reinforcement learning.” arXiv preprint arXiv:2004.07219 (2020).