Reinforcement Learning for Recommendation Systems
While traditional recommendation methods have significantly improved user experience, they are often myopic and need a constant feedback loop to the user. In this implementation, we use Offline Reinforcement Learning to build an agent that can recommend music tracks to a user to minimize the skip rate. We leverage open-sourced Spotify data to build an environment using item embeddings, simulate the rewards based on skips in the user session, and train an agent on this offline data of sequential user interaction. The underlying agent utilizes LIRD, an implementation of the Deep Deterministic Policy gradient algorithm, to optimize recommendations. The reward is received from user behavior when deployed online and simulated during training. The model outperforms the baseline model in minimizing the skip rate and generates diverse recommendations.
- Introduction
- Case Study
- How to model it as an RL system
- Reinforcement Learning Framework
- Metrics and Results
- Limitations
- Conclusion and Future Work
- References
Introduction
Recommendation technologies have become increasingly popular over the years with application scope in diverse domains like movies, music, books, and social media [1, 2]. The early recommendation research primarily focused on developing content-based and collaborative filtering-based methods [3], [4] to recommend those items most relevant to the user. Although relatively intuitive and straightforward to implement, these recommendation techniques have pitfalls. Firstly, they fall prey to the myopic recommendation that maximizes immediate (short-term) rewards, overlooking recommendations that will lead to future profitable (long-term) rewards. Secondly, these traditional systems are static; they follow a fixed recommendation strategy that does not consider the dynamic nature of user preference. Lastly, they are prone to system bias as they observe feedback for only those items that the user has encountered.

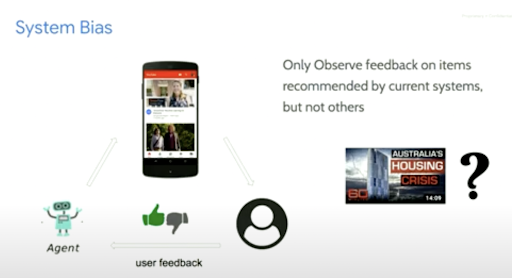
These figures are taken from the YouTube recommendation system case study [5]
Modeling recommendation systems via Reinforcement learning (RL) help mitigate these issues. Firstly, an RL agent’s optimal strategy is maximizing users’ expected long-term cumulative reward. Secondly, the RL agent continuously updates its strategy during user interactions until the system converges to an optimal policy that generates recommendations best fitting users’ dynamic preferences. Lastly, we can simulate the reward for the user-item interaction that has not occurred in reality, thereby overcoming the system bias issue.
Nevertheless, RL comes with its own set of implementation hurdles. In an RL-based recommendation system, the state models the user history and relevant context for a recommendation, and the action model the recommended items, and the user feedback models the actions’ reward or goodness value. In the last decade, recommendation systems have been scaled up in the industry, such as recommending videos on YouTube and music on Spotify, which consists of millions of videos and songs, respectively, with an ever-growing repository. This results in a large action space (recommendation set), making RL on it a challenge. Further, while an RL agent learns to recommend, it may start by making random irrelevant recommendations, which can impact users’ trust in the platform. This makes online learning expensive and infeasible, and the agent can only be allowed to learn interactively once it can predict user preference with a certain degree of accuracy. Due to this, we need to employ the offline reinforcement learning method, which has several implementation challenges, one of the major ones being the distribution shift. Moreover, we are dealing with a partially observable environment in which we do not have an explicit representation of user interests; instead, we attempt to approximate it. Lastly, we have feedback (reward) for only those items with which the user interacted. Hence, the rewards are highly sparse.
In this project, we work on the use case of Spotify music recommendations, precisely predicting skips in Spotify streaming data. We work on the dataset presented in the Spotify Sequential Skip Prediction Challenge[6]. We showcase how to model a recommendation system as an RL problem while taking due consideration the challenges mentioned above. The rest of the blog is structured as follows: explain the Spotify use case and dataset, how to create the environment from the data (action representation, state representation, and reward simulation), RL methodology applied to solve the problem, metrics and results, conclusion, and future work.
Case Study
For our project, we studied the implementation of LIRD (Deep Reinforcement Learning for List-wise Recommendations) [7] on a dataset from Spotify. The dataset was released as part of an AI Crowd competition. The competition’s goal was to predict sequential skips in a user session. The goal of the implementation was to build a recommendation system that generated recommendations and minimized the number of skipped tracks in a recommended slate.
The goal of the implementation was to build a recommendation system that generated recommendations and minimized the number of skipped tracks in a recommended slate.
There were two datasets released: User sessions and Track Data. The exhaustive data set consisted of 130 million listening sessions with quantified user interactions on the Spotify service. The track data consisted of nearly 4 million tracks during these sessions with Spotify-generated features like danceability, accousticness, cadence, etc., and metadata for all of these tracks.
As in Offline RL, the dataset is, in turn, configured to mimic a traditional RL set-up: declaring an environment, a recommender agent and formulating immediate returns and long-term rewards.

How to model it as an RL system
The following subsections dive deep into modeling the Spotify recommendation problem as a reinforcement learning problem. We base our environment simulation on the work proposed in Deep Reinforcement Learning for List-wise Recommendations [7].
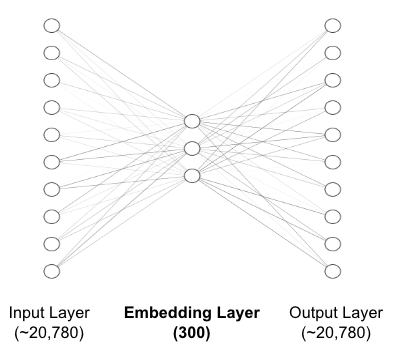
Item Embedding
In our training data, there are a total of ~20,780 tracks (i.e., items). In order to generate user context item embeddings, we remove one random track from each session, and the randomly removed song becomes the output of the embedding network. Both the inputs and outputs to the embedding network are one-hot encoded and have nodes equal to the total number of distinct tracks. We train this network on all the available sessions to generate an embedding of dimension 300.
Environment
The input to the environment is the current state of a user and selected action. When the recommendation system is applied online, we get rewards from the user’s response. However, to train the framework offline, we simulate online rewards based on users’ historical behavior.
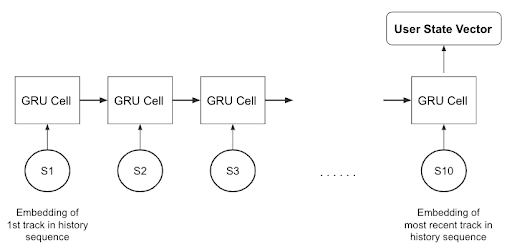
State Space
A state is defined as the previous 10 tracks that the user interacted with before. The items in the state are sorted in chronological order.
Action Space
An action is to recommend a list of tracks to a user based on the current state. In our case, we recommend the top 3 tracks to a user each time.

Reward
The user’s feedback on the recommended tracks is the reward. If the track is skipped, then the a reward is 0; otherwise, it is 1.

Transition Probability
If the user skips all the recommended tracks, then the state remains the same; otherwise, it is updated. Each time a user does not skip some tracks in the recommended list, we add them to the end-of-state and remove the same number of tracks at the top of the state since we keep a fixed length state.
Reward Simulation
We create an online user-agent interaction environment simulator to train our framework offline. This simulator immediately predicts a reward based on the user’s current state and action. We match the current state-action pair to the existing historical records and stochastically generate a simulated reward.
There are 8 possible scenarios in our case since we recommend 3 tracks each time, and each
can either be skipped or not. We average the state-action pairs after normalization for each of these scenarios in the historical records. Then we calculate the similarity of the current state-action
pair to each existing representative state-action pair using cosine similarity.
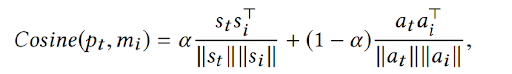
Here, the first term measures the state similarity, the second term evaluates the action similarity, and the parameter controls the balance of two similarities. Then, we normalize the similarity scores for each scenario to get probabilities using the below equation.
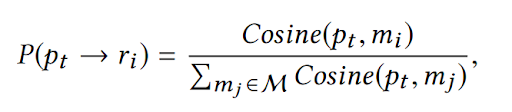
In practice, a reward is usually a number rather than a vector. The reward at the top of the recommended the list has a higher contribution to the overall rewards with a discounting factor for subsequent rewards according to the following equation.
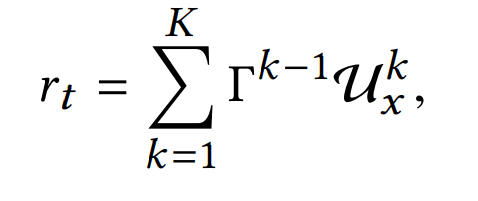
The final cumulated reward is then calculated by taking a dot product of the probability and reward values for each scenario.
Reinforcement Learning Framework
We use Deep Deterministic Policy Gradient(DDPG) [8] based actor-critic learning framework for this task. Further, we refer to this repository for our implementation [9].
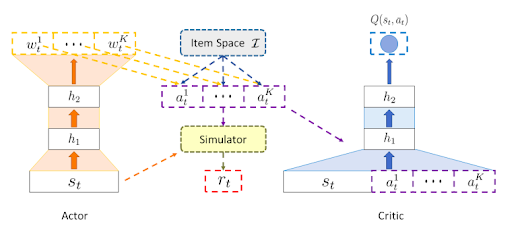
Actor Framework
The Actor framework consists of two steps,
- State-specific scoring function parameter generating
- Action generating
The Actor first generates weight vectors by mapping the current states to a list of weight vectors using a deep neural network. In the second step, for each weight vector, the recommender scores all items in the item space and selects the item with the highest score. In our case, the Actor generates a list of three weight vectors, each corresponding to a recommendation.

Critic Framework
The Critic is designed to leverage an approximator to learn an action-value function, which is a judgment of whether the action generated by the Actor matches the current state. Then, according to the action-value function, the Actor updates its parameters to improve performance to generate proper actions in the following iterations.
Training
In each iteration, there are two stages,
-
Transition generating stage: Given the current state, the recommender agent first recommends a list of items. The agent then observes the reward from the simulator and updates the state, and finally the recommender agent stores transitions into the memory.
-
Parameter updating stage: The recommender agent samples a mini-batch of transitions from memory and then updates parameters of the Actor and Critic following a standard DDPG procedure.
In the training process, we also leverage widely used techniques to train our framework, like experience replay, prioritized sampling strategy.

Metrics and Results
Diversity
It measures the average dissimilarity between all pairs of recommended items. It is a tradeoff between localized (best per user) vs. global (best across users) recommendations.
We compare the acoustic features - acousticness, beat strength, bounciness, danceability, energy, liveness, speechiness, valence - for each pairing between the recommended tracks using cosine similarity and take a mean across it.
We formulate similarity and diversity as follows:
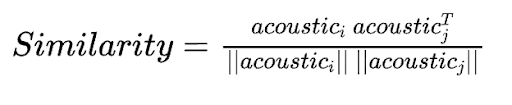
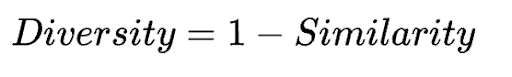
We then predict the recommended songs for each user in the test set and obtain an average diversity of recommendation of 10.6% over multiple evaluation runs.
Skip Rate
The Skip Rate gives an average measure of the percentage of recommended songs that were skipped. It is formulated as follows:
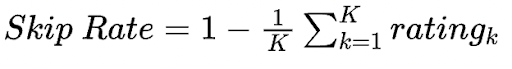
Here k is the size of the test set for RL and the entire dataset for baseline.
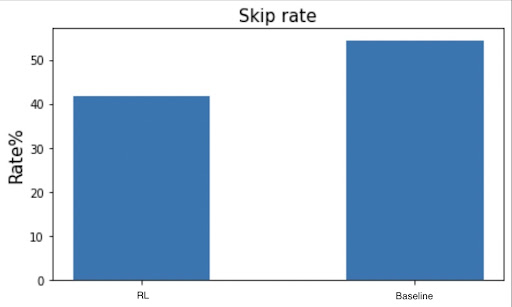
For the baseline, we use the entire dataset to obtain the average skip rate of songs across all the data samples and contrast it with how the DDPG framework recommendations affect the skip rate. The aim is to minimize the Skip rate, which would reflect the goodness of the recommendation. We obtain a Skip rate of 42.3% for the DDPG framework and 54.4% for the baseline and present the following graph for comparison.
Limitations
One of the significant limitations of this work is the imperfection and complexity of environment simulation. An ablation study on the hyperparameters: Alpha which weighs the contribution of state and action similarity in reward simulation, Tau which discounts the rewards across the recommended set (least discoutning to top recommendation and most to bottom one), Gamma discount the RL rewards over timesteps and Size of the replay memory, yielded insignificant improvements in the metrics discussed above.
Conclusion and Future Work
We demonstrate how to simulate the Spotify next track recommendation system as Reinforcement. Learning problems and applying a DDPG framework to obtain an agent that can recommend a list of soundtracks for users based on their listening history. We obtain an average diversity of 10.6% in the recommendation set and decrease the average skip rate by about 12% from the baseline. However, the approach has limitations.
As part of continued work, we aim to explore new formulations for reward and alternate approaches for training the agent, like Top K Reinforce with Off-policy correction method [10], which has proven to be successful for YouTube recommendations. Finally, we will evaluate the methods on Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG). Metrics, which are more quantitative and objective ways to test the accuracy of the recommendation system.
References
[1] Lin, Yuanguo, et al. “A survey on reinforcement learning for recommender systems.” arXiv preprint arXiv:2109.10665 (2021).
[2] Bobadilla, Jesús, et al. “Recommender systems survey.” Knowledge-based systems 46 (2013): 109-132.
[3] Adomavicius, Gediminas, and Alexander Tuzhilin. “Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions.” IEEE transactions on knowledge and data engineering 17.6 (2005): 734-749.
[4] Shi, Yue, Martha Larson, and Alan Hanjalic. “Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges.” ACM Computing Surveys (CSUR) 47.1 (2014): 1-45.
[5] https://www.youtube.com/watch?v=HEqQ2_1XRTs
[6] Brost, B., Mehrotra, R., and Jehan, T. “The music streaming sessions dataset”, In Proceedings of the 2019 Web Conference. ACM, 2019
[7] Zhao, X., Zhang, L., Ding, Z., Yin, D., Zhao, Y., and Tang, J. “Deep reinforcement learning for list-wise recommendations” CoRR, abs/1801.00209, 2018.
[8] Lillicrap, Timothy P., et al. “Continuous control with deep reinforcement learning.” arXiv preprint arXiv:1509.02971 (2015).
[9] https://github.com/paige-chang/Music-Recommendation-System
[10] Chen, Minmin, et al. “Top-k off-policy correction for a REINFORCE recommender system.” Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.