Speed up Autonomous Driving with Safe Reinforcement Learning in Metadrive
In MetaDrive, safety is the first priority. We want to explore how to speed up auto-drive agents with Safe Reinforcement Learning and find the optimal speed in diverse driving scenarios.
- Introduction
- Objective
- Approach
- Experiment and result
- Discussion and Comparison
- Conclusion
- Future work
- Record video
- Relevant Papers
Introduction
Reinforcement Learning (RL) is widely used in safe autonomous driving. MetaDrive [1] is a driving simulation platform that composes diverse driving scenarios for generalizable RL. In MetaDrive, safety is the first priority, where agents were trained to ensure the driving safety in diverse driving scenarios. However, safety is overemphasized at the expense of speed. For example, when there is traffic, an agent may keep the speed as low as possible and not overtake other vehicles. Imagine there is a busy driver who wants to pass through the traffic flow and arrive the destination in the shortest amount of time with safe driving. How can we achieve that in MetaDrive? So we are going to explore how RL can have agents achieve fastest speed with safety guaranteed.
Objective
Explore how to speed up auto-drive agents with safe RL and find the optimal speed in diverse driving scenarios.
Approach
In terms of maximizing speed, [2] and [3] used deep RL to optimaze car racing. Although speeding up our agents is far from racing, we can research into the two papers and leverage deep RL to optimize speed in our case. We found [4] and [5] are helpful to reference in developing safe RL methods.
CoPO[6] is multi-agent reinforcement learning algorithm on top of MetaDrive. With CoPO, we can speed up vehicles in a multi-agent environment and we shift our focus to the collective speed and safety of all vehicles in the environment. Note that each vehicle is an agent and is put in the same MetaDrive environment. Under the MetaDrive environment, we looked into the reward function and adjust the reward for speed. We updated reward function in order to obtain an agent with faster speed and relatively high safety.
\[R=c_1R_{driving}+c_2R_{speed}+R_{termination}\]We increased the maximum speed limitation of vehicle. At the same time, we increased the speed reward factor \(c_2\) to emphasize the importance of speed, and thus the vehicle will be encouraged to take more acceleration as long as the safety factor is satisfied. Moreover, we reset “use_lateral_reward” to explore whether vehicles keep in lane has an influence on the speed. The newly updated reward function is used to in training process to generate the policy function.
We found MetaDrive uses RLLib to train RL agents. Ray 2.1.0 in RLLib is used to train and generate policy parameters with the PPO reinforcement training method under 22 environments for a large amount of episode, and the parameters are saved in the local folder. We also found MetaDrive uses expert class to read and make use of the trained data (e.g. weight), which returns the vehicle’s current observation and continuous action to AI policy function. The trained policy function fits the fast and safe targets in the environment.
Without touching the details of the training of MetaDrive, we took advantage of trainers for different algorithms in CoPO. After adjusting parameters, we directly ran train_all_[algorithm].py (with the algorithm of our choice) to train the model.
Experiment and result
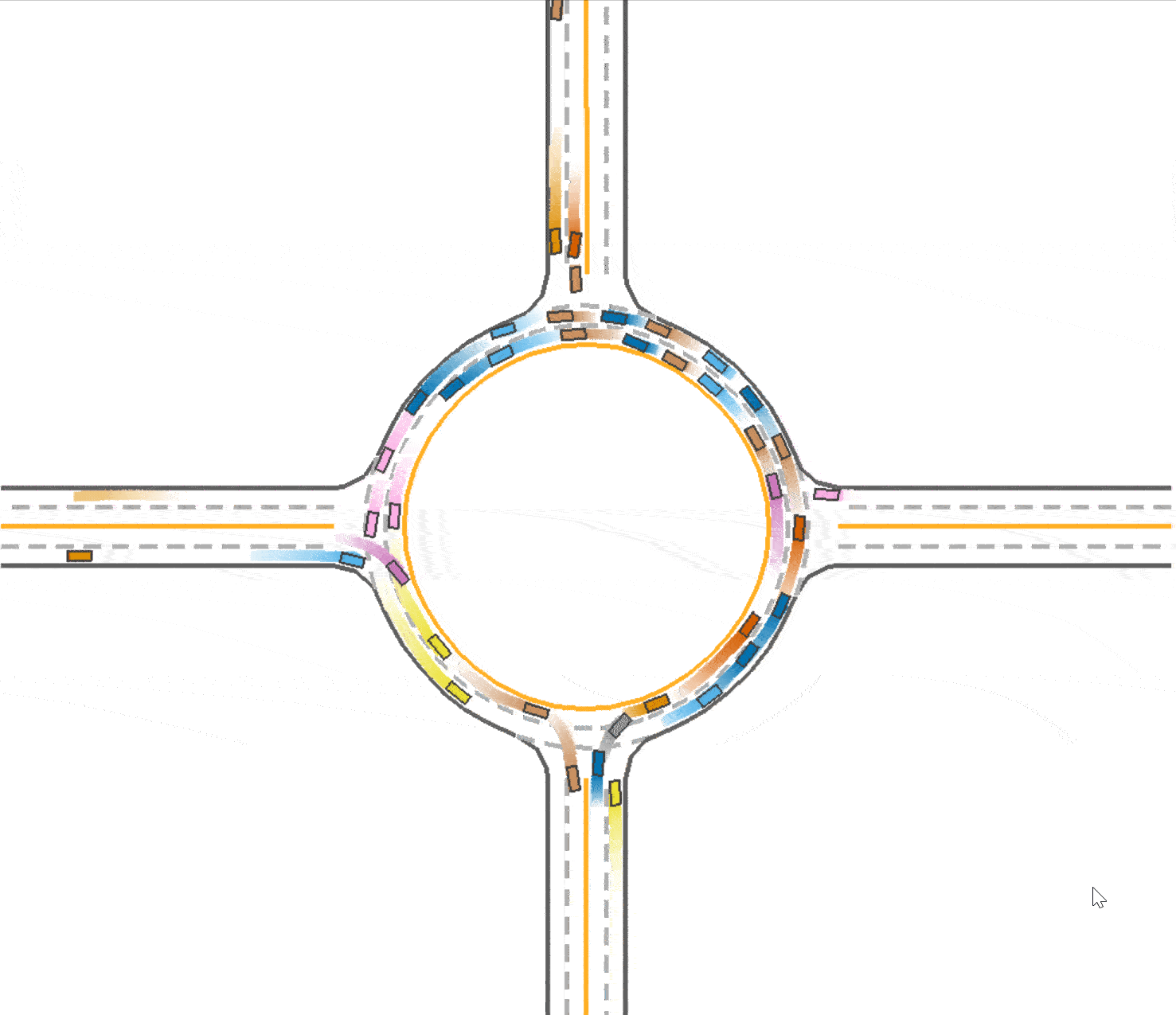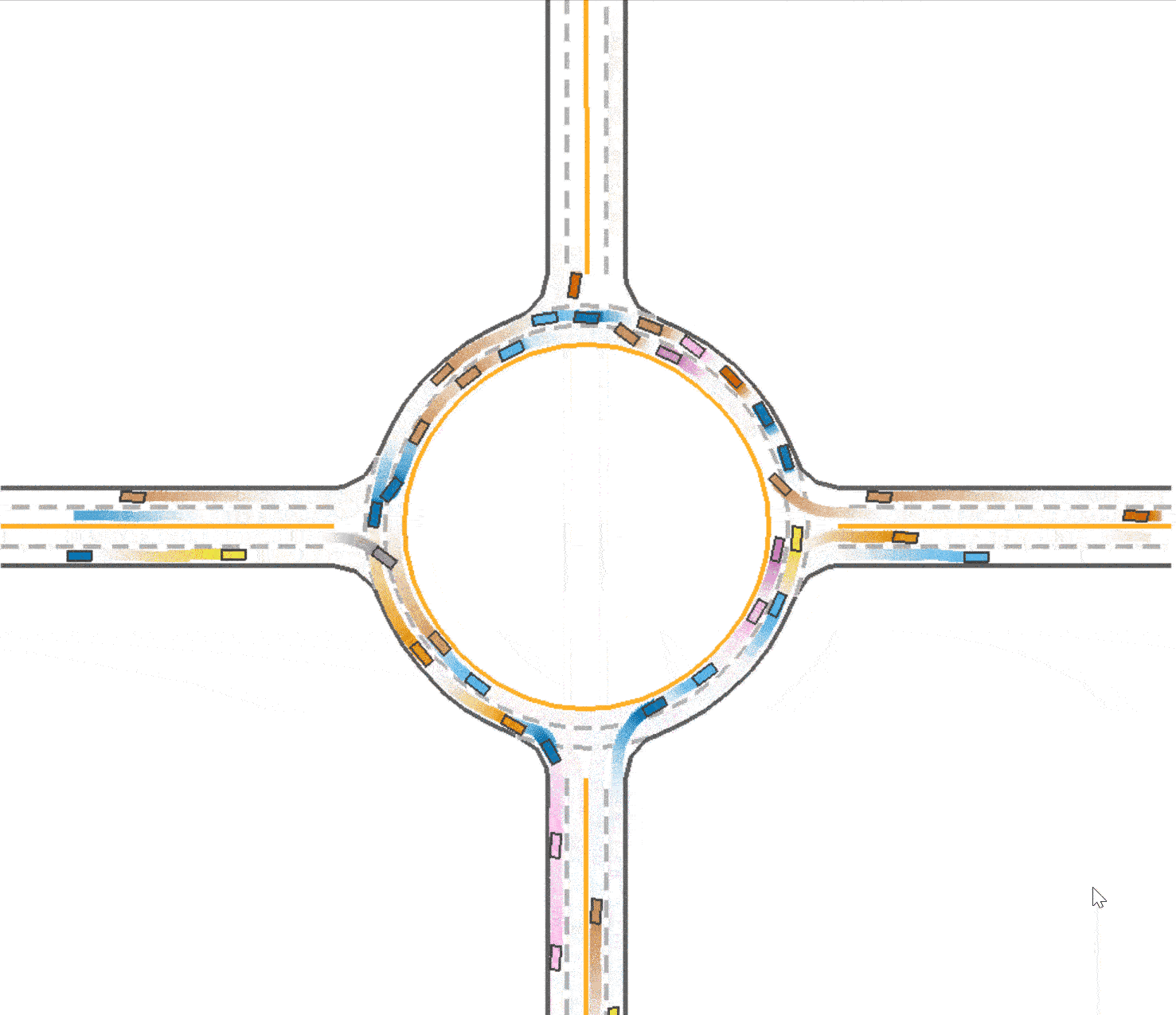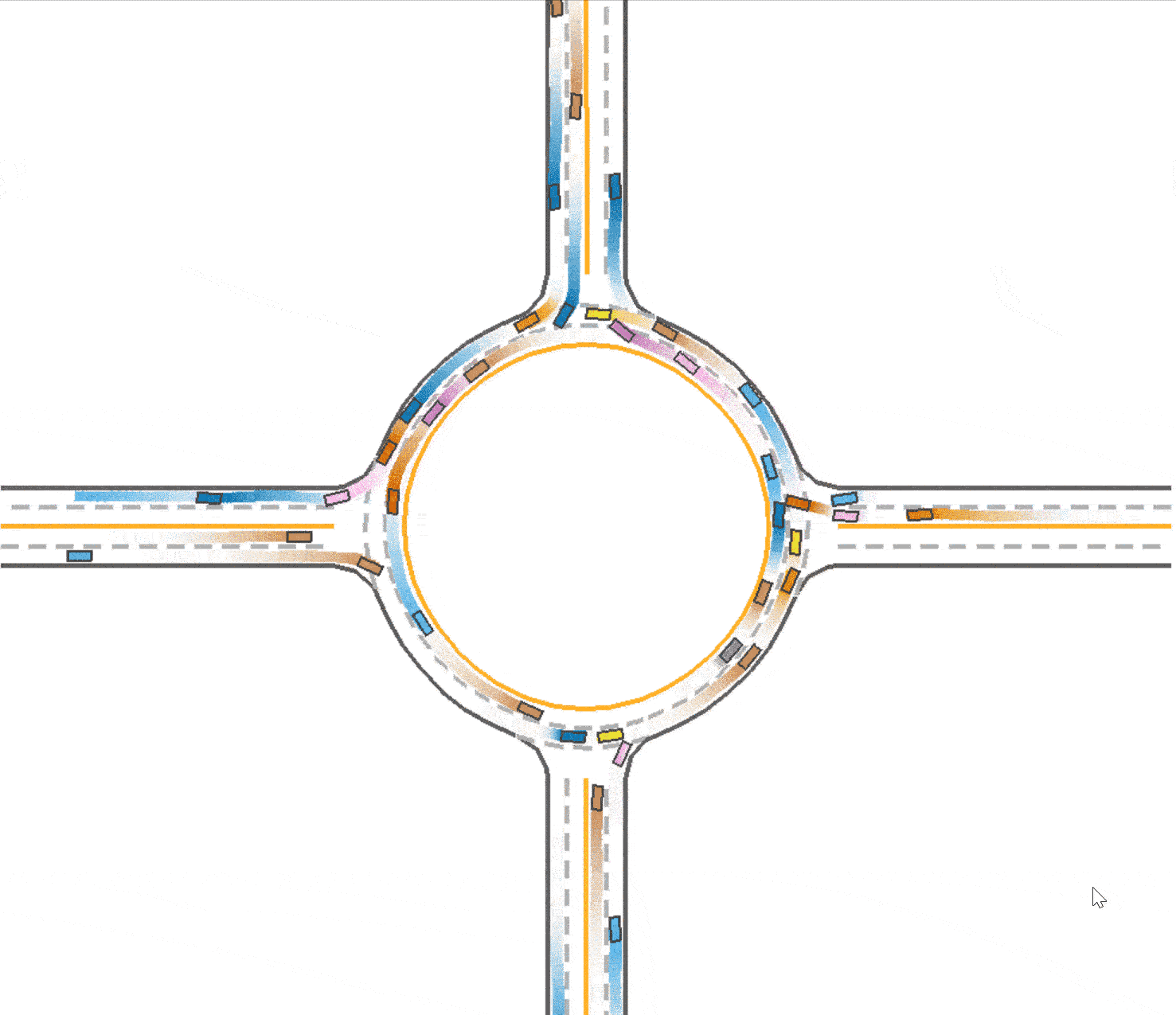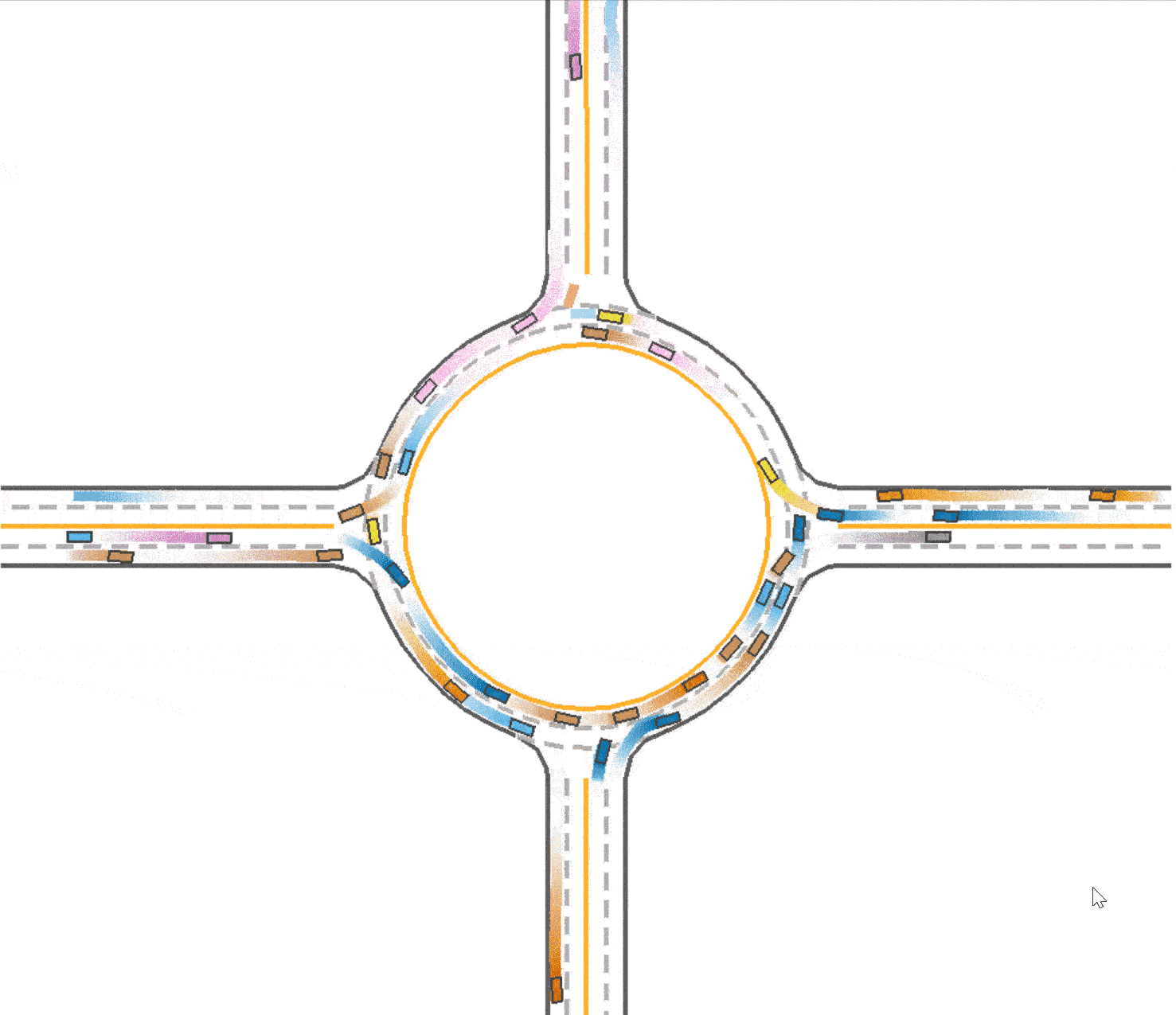
In our experiment, we focus on one environment, which is the roundabout environment, since it is relatively more complex than other environments such as intersection. We chose IPPO as the algorithm that we train our model with, where IPPO is Independent PPO used for multi-agent reinforcement learning, since we are familiar with PPO in our lecture. We define our baseline to be the pretrained model with IPPO algorithm in roundabout environment. We will use success rate as one of our evaluation metrics to judge the performance of experiments, since we want to keep relatively high safety while speeding up the agents. To evaluate the speeding up, we are going to measure the total running time of all agents entering and exiting the environment. Pratically, We time the runtime of the scene until all vehicles exit the scene and disappear.
Experiment process
Controlling variable method would be used to make accurate comparison of results. In order to achieve our objective, the experiment includes 5 steps for each environment basically:
- Use the functions provided by Rllib and Tune, which are python packages for reinforcemnet agent training. After that, we could train the IPPO trainer in the roundabout environment with 1,000,000 steps. 1,000,000 steps are sufficient for the model to peak at the highest success rate.
- Use the best checkpoint during training process with the highest success rate to perform runtime experiment. Since the training may overfit when the training step is too large (after 700,000 steps), we need to evaluate and find the best checkpoint during the training process and return a policy function. Fortunately, the trainer will store the checkpoints with top 3 highest success rates.
- In order to obtain the action in specific situation, observation and done function (o,d) is input into the policy function.
- The action generated by policy function is given to the simulation environment and step into the next state.
- The total running time and success rate could be calculated for each episode when all agents terminate (which could be crash, out of road or reach destination). The data could be collected and analyzed.
Baseline
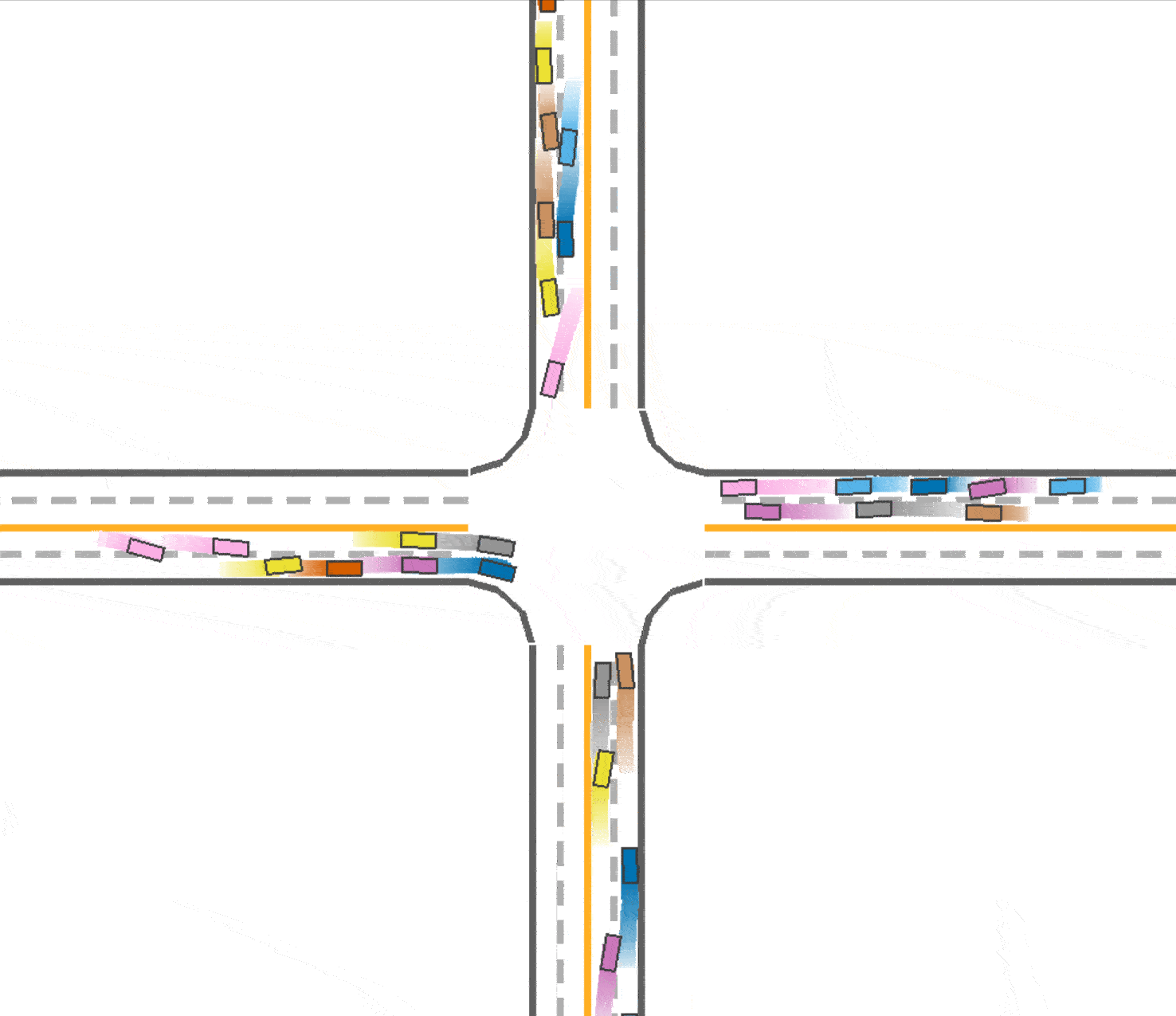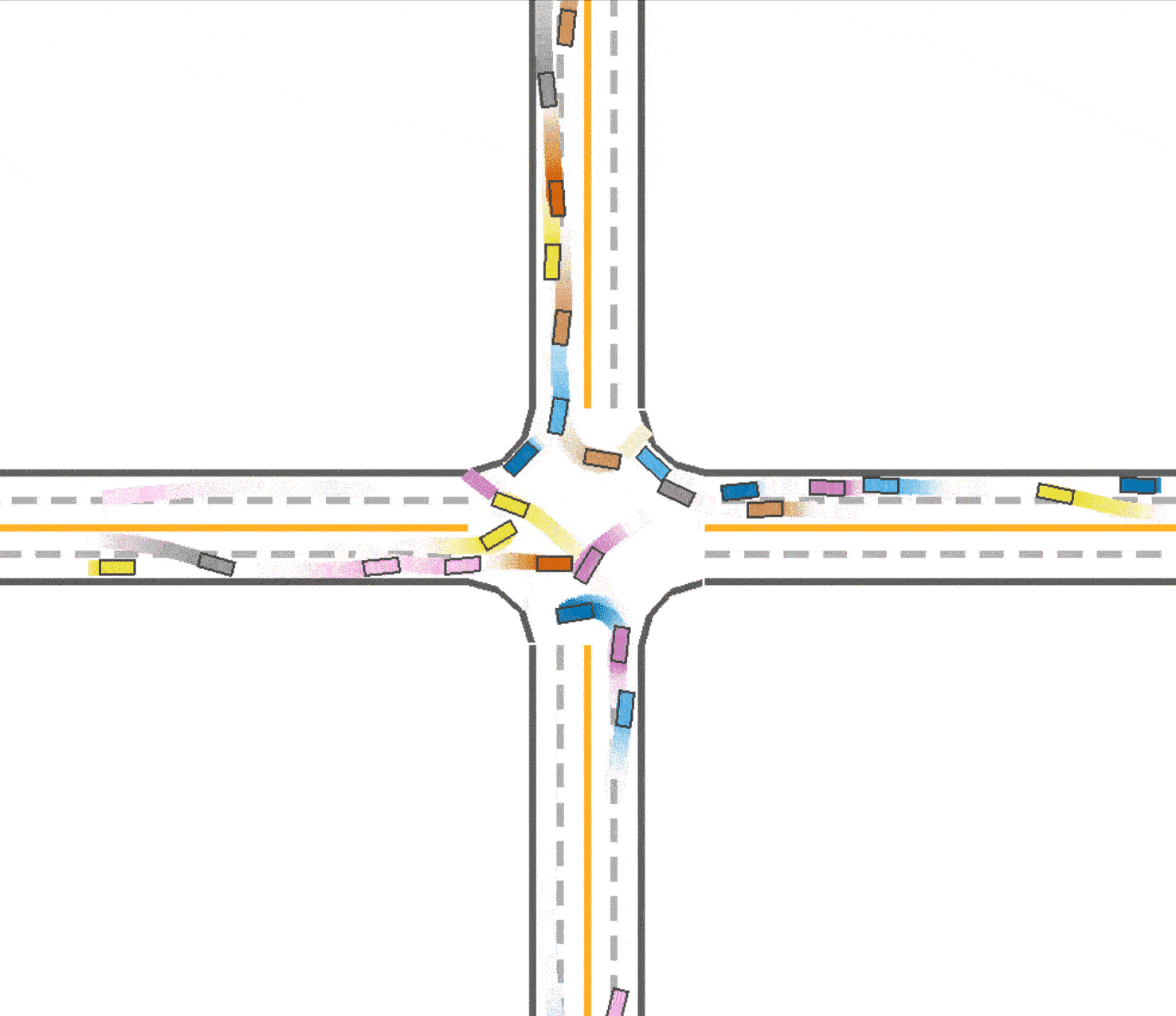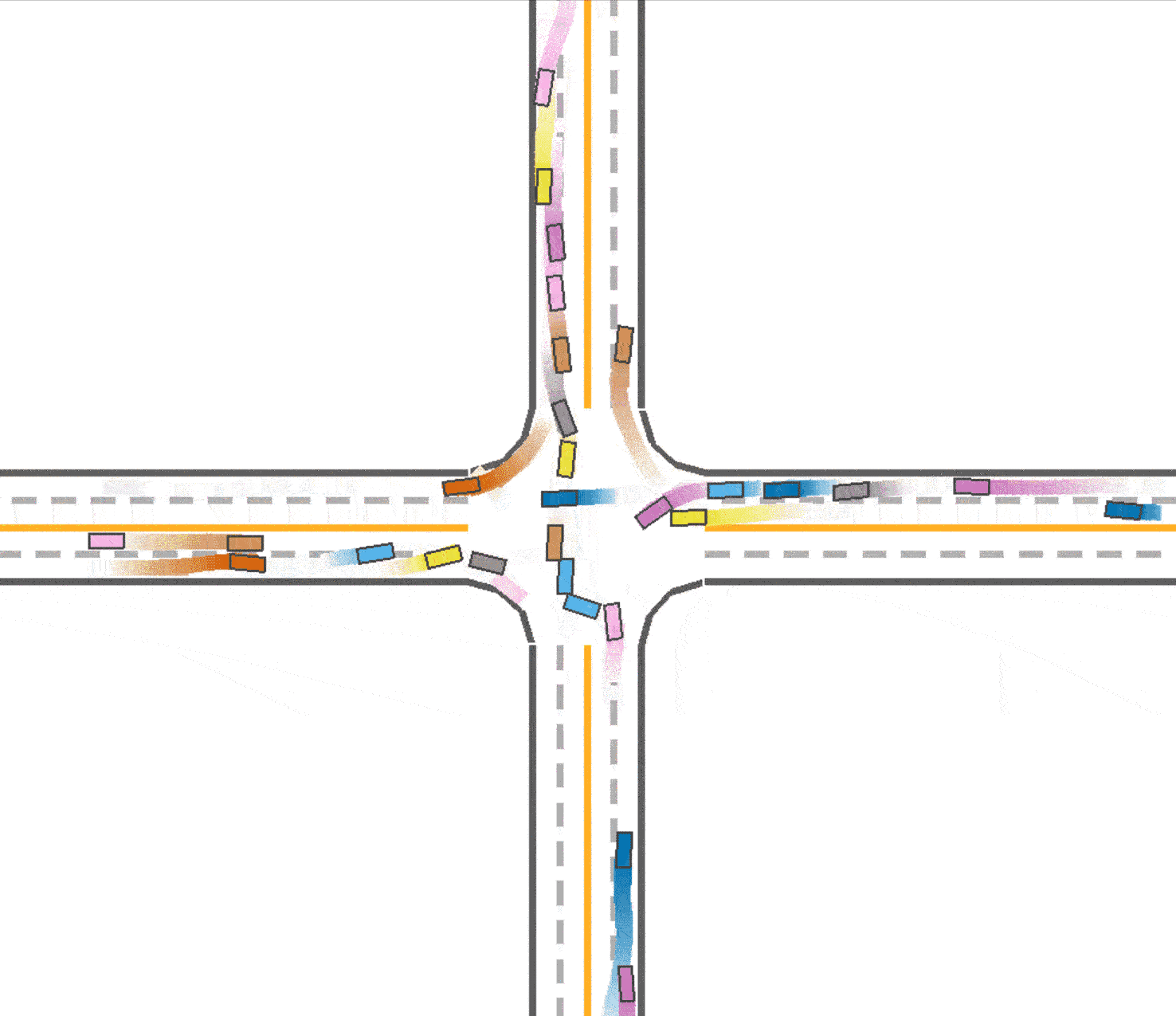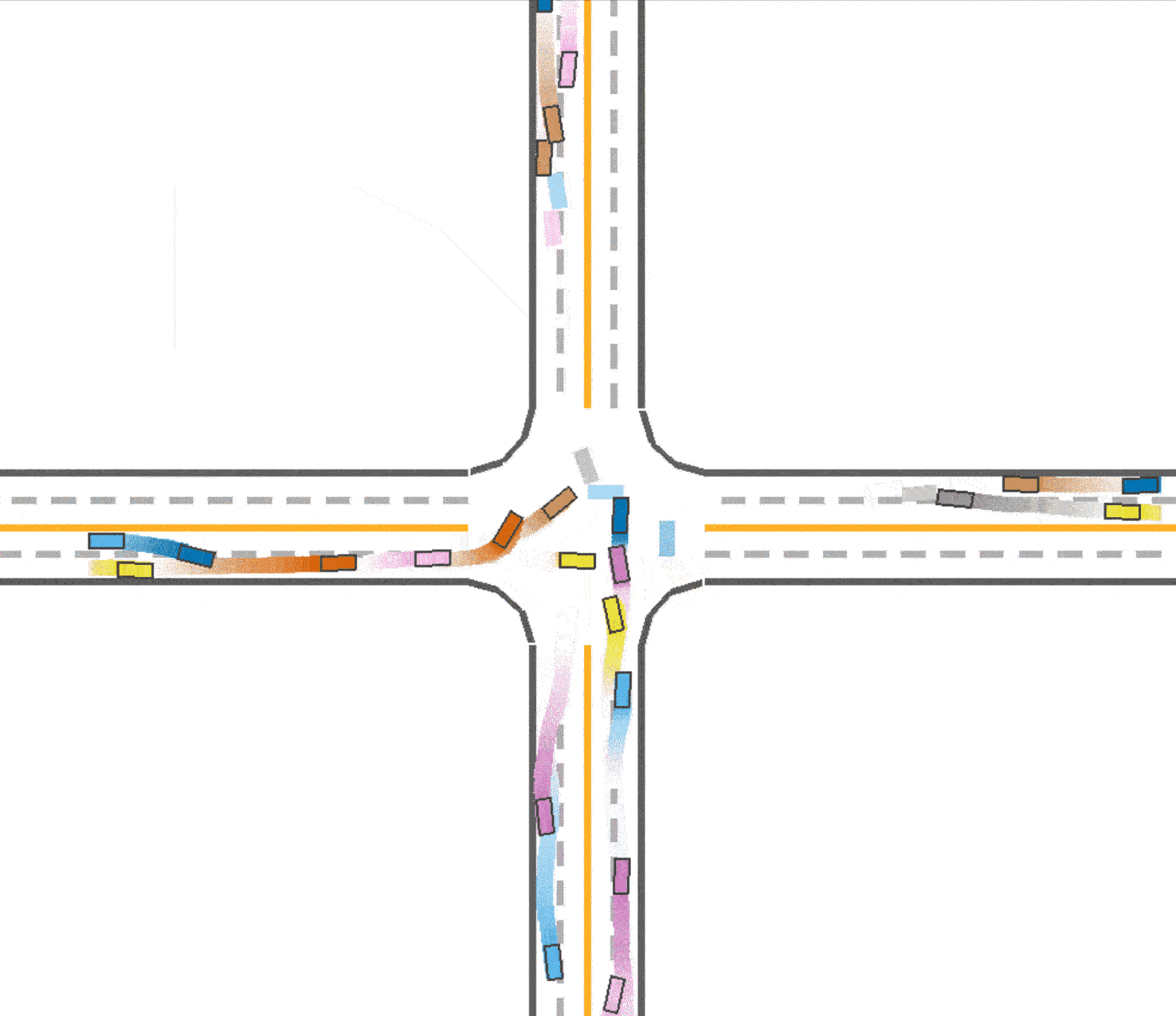
The baseline of our experiment (trained with IPPO algorithm in roundabout environment) achieves 0.757 success rate and takes 62.6 seconds with 40 agents. Below is a visualization of the baseline.
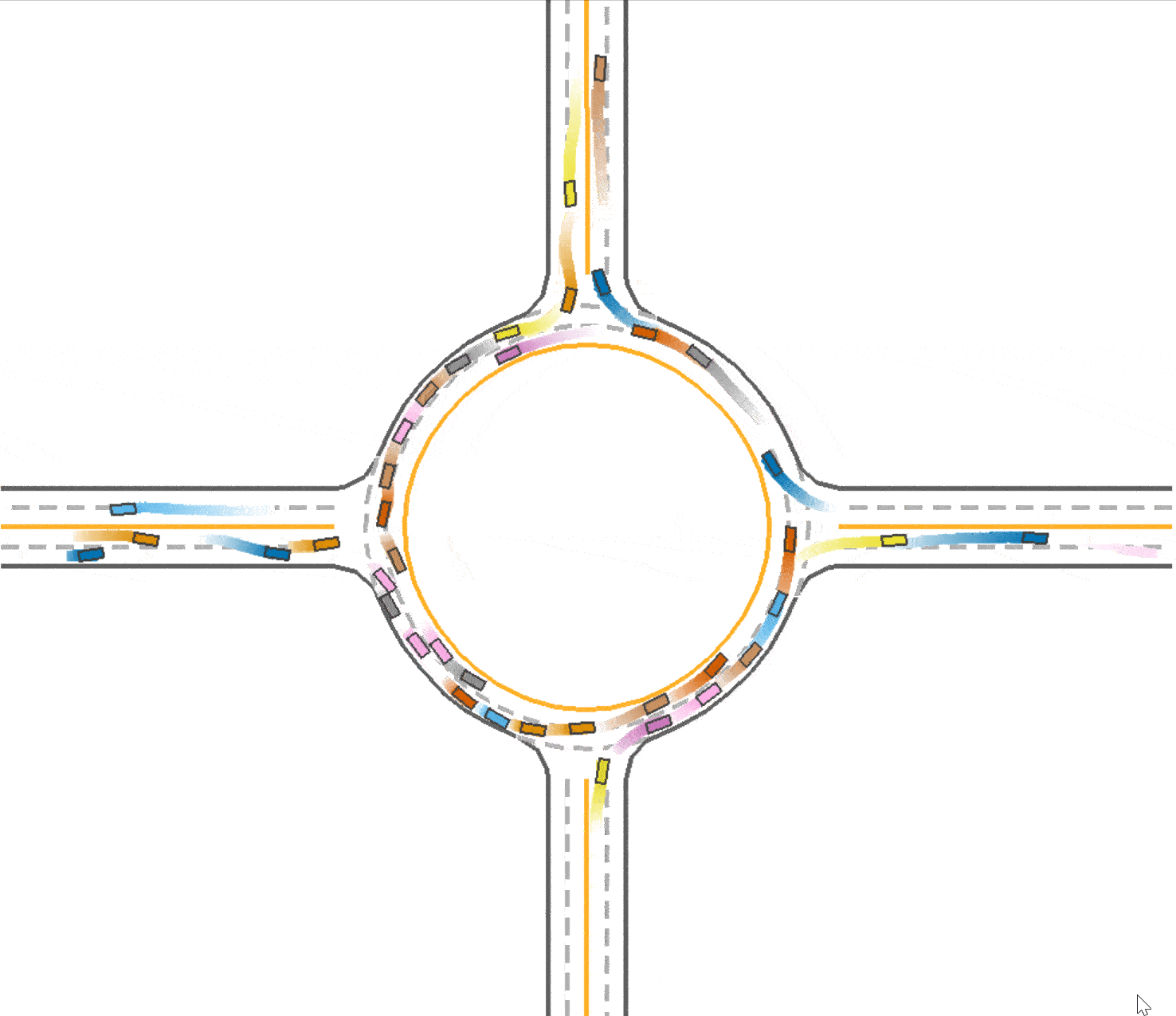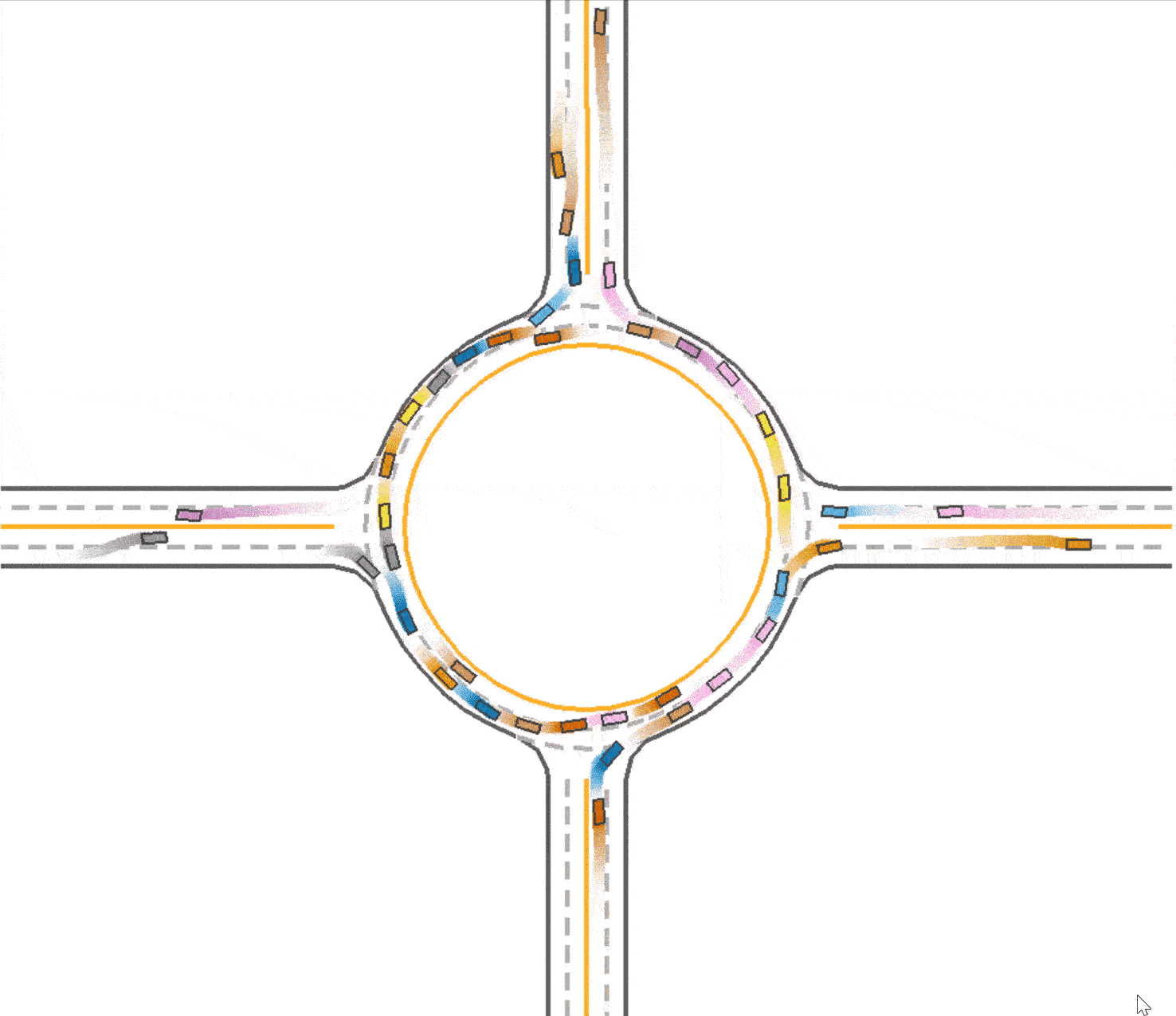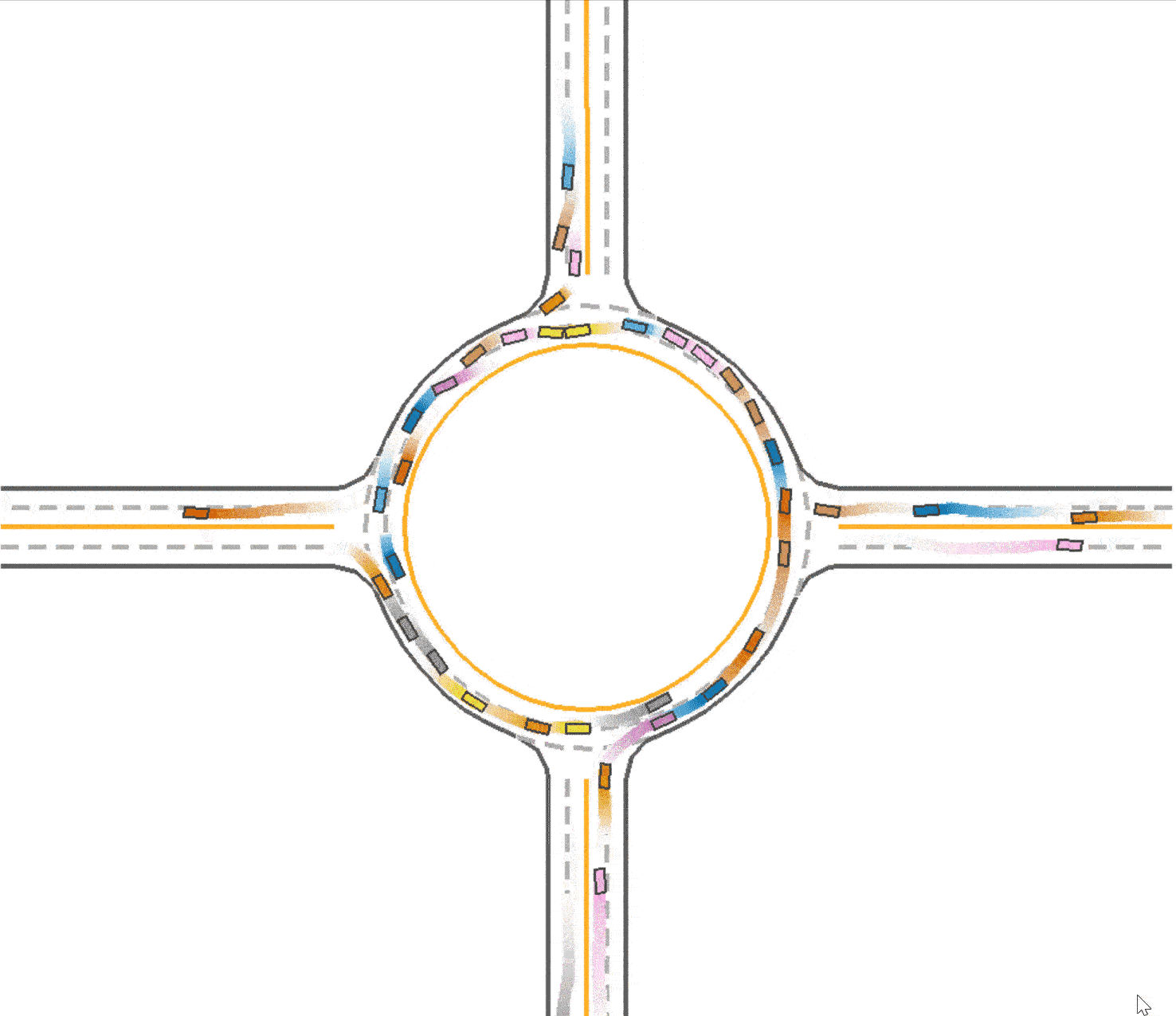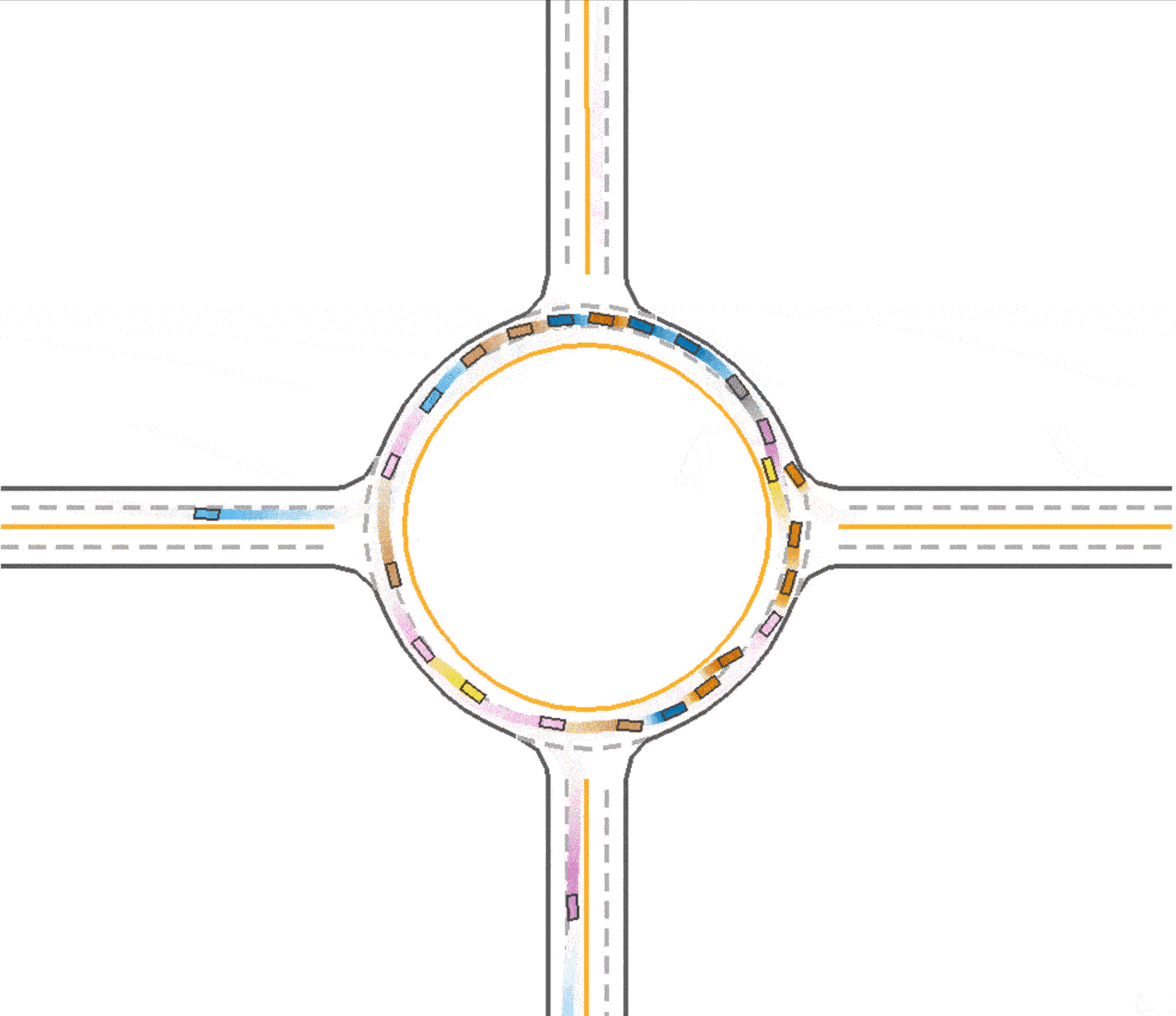
Use lateral reward in training
We observed that in the baseline (Fig 1), the vehicles tend to drive in the middle of the road which prevent vehicles behind them from speeding up or overtaking. At the same time, this trained vehicles prefer to drive in the outer lane of the roundabout and not to takeover because of safety consideration. We think this is a kind of waste of traffic resources since the inner lane is always empty, and this may also be one reason that leads the slow speed of the traffic. Therefore, with the use of lateral reward, the car would learn to keep in the lane, so that the traffic flow could be divided into 2 lanes and use the traffic resources sufficiently. And thus the vehicles are able to speed up since there are less car in one lane. To enable the use of lateral reward, we set the parameter use_lateral_reward=True in config.
Fig 2 is the progress of the training process with lateral reward. The success rate keeps an increaseing trend with a small dip at 400,000 and it peaks at nearly 700,000 step.
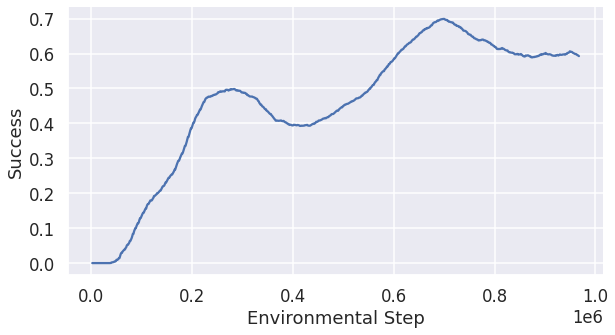
The result of the model with lateral reward with 40 agents is that the success rate is 0.749 and the total running time is 59.1 seconds, which suggest a speed-up of the traffic.
Compared to the baseline (Fig 1), it could be found that the vehicles are divided into 2 lanes so the traffic resource are utilized better (as shown in Fig 3), which explained the improvement in the total running time (59.1 seconds). However, due to the reason that the outer vehicles and inner vehicles are more likely to drive in the same pace, it is much easier to cause a crash. Therefore, the success rate declines slightly to 0.749.
Increase speed reward in training
To speed up the agents in the roundabout environment, we can directly increase the speed reward to force the agents to drive faster. However, higher speed will cause higher probability of crashes and running out of road. So at the same time of increasing speed reward, we adaptively increase the success reward to emphasize the importance of avoiding crashes or running out of road during the training process. We also increased the penalty of crashes and running out of road to attempt to retain the safety. To reset the rewards and penalties, we can dirrectly reset the parameters speed_reward, success_reward, out_of_road_penalty, crash_vehicle_penalty and crash_object_penalty in the config of metadrive_env.py. Note that the values in the baseline are speed_reward=0.1, success_reward=10.0, out_of_road_penalty=5.0, crash_vehicle_penalty=5.0 and crash_object_penalty=5.0.
In the testing, we varied the number of agents to explore if the running time can be different under the circumstances with different number of vehicles.
Training with speed_reward=0.2
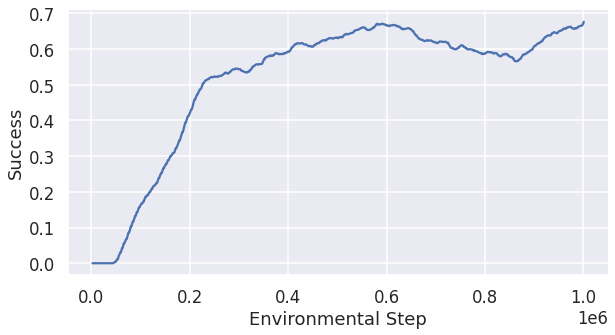
In the first experiment, we increased the speed reward to 0.2, which doubled the original value, while keeping other parameters the same. It turned out doubling the original speed reward is a little aggressive, as the success rate for 40 agents dropped dramatically to 0.634 and the total running time only decreased to 58.8 seconds. Fig 4 is the change of the success rate in the training process over steps.
Training with speed_reward=0.12 and success_reward=12.0
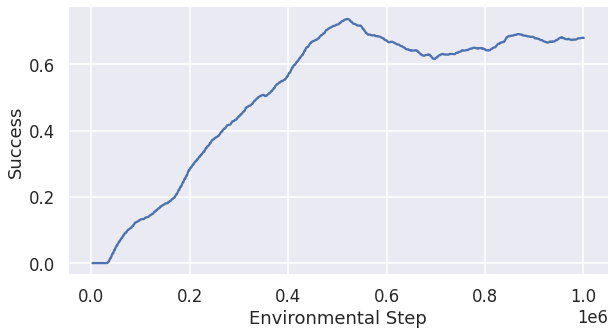
We tried to be conservative in the second experiment, where we increased the speed reward to only 0.12 and to remain the safety level, we increased the success reward to 12.0. This configuration generated better result in the setting of 40 agents: it achieved 0.695 success rate and the corresponding total running time is 58.79 seconds. The success rate increased compared to the last experiment with speed_reward=0.2. Fig 5 is the change of the success rate in the training process over steps.
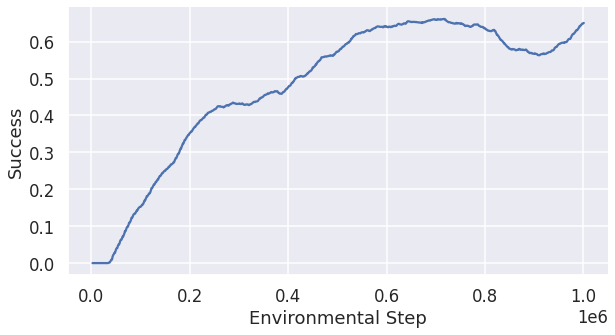
Training with speed_reward=0.15 and success_reward=12.0
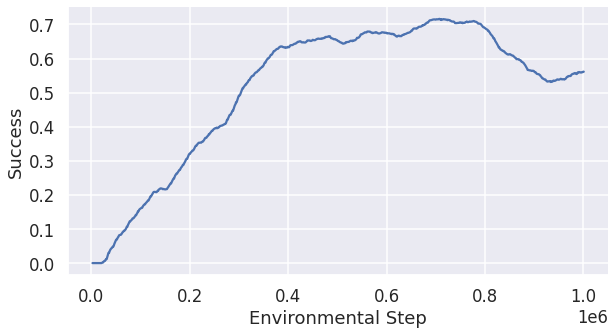
We think speed_reward=0.12 is too conservative and thus we increased the success reward to 0.15 while keeping the success reward the same as in the last experiment. Fig 6 is the change of the success rate in the training process over steps. The success rate for this configuration for 40 agents is 0.703 and the corresponding total running time is 56.6 seconds.
Training with speed_reward=0.18, success_reward=15.0, out_of_road_penalty=7.0, crash_vehicle_penalty=7.0 and crash_object_penalty=7.0
We want to explore if we can increase the speed reward futher. We decided to increase the speed reward to 0.18. In return, the success reward is increased to 15.0. In this experiment, we also increased the penalties to 7.0 to offest the high risk of crashes introduced by the high speed reward. Fig 7 is the change of the success rate in the training process over steps. The result for 40 agents is that the success rate is 0.697 and the total running time is 60.67 seconds. The running time did not go down compared to the last experiment. We think it might be because the increased penalties forced agents to take more safe actions and thus slowed down the traffic.
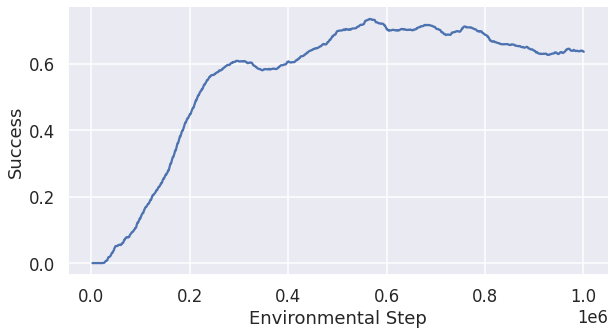
Training Coordinated Policy Optimiztion (CoPO) with speed_reward=0.15 and success_reward=12.0
We observed speed_reward=0.15 and success_reward=12.0 with IPPO generated the best result compared to the other experiments above. Thus we want to generalize this parameter configuration to another algorithm. We chose Coordinated Policy Optimiztion (CoPO) to run the training with speed_reward=0.15 and success_reward=12.0, since it is the best algorithm in the paper. Fig 8 is the change of the success rate in the training process over steps. The result for 40 agents is that the success rate is 0.7516 and the total running time is 75.3 seconds. We also ran the pretrained CoPO model as the baseline for comparison and got the result for 40 agents is that the success rate is 0.802 and the total running time is 84.36 seconds.
Results for different number of agents
we varied the number of agents to explore if the running time can be different under the circumstances with different number of vehicles. And Table 1, Table 2 and Table 3 compare the models on different number of agents (40, 20 and 10) in the roundabout environment.
| Success rate | Total running time (s) | |
|---|---|---|
| baseline | 0.757 | 62.6 |
| lateral reward=True | 0.749 | 59.1 |
| speed_reward=0.12, success_reward=12.0 | 0.695 | 58.79 |
| speed_reward=0.15, success_reward=12.0 | 0.703 | 56.6 |
| speed_reward=0.18, success_reward=15.0, penalties=7.0 | 0.697 | 60.67 |
| speed_reward=0.20 | 0.634 | 58.8 |
| CoPO, baseline | 0.802 | 84.36 |
| CoPO, speed_reward=0.15, success_reward=12.0 | 0.7516 | 75.3 |
| Success rate | Total running time (s) | |
|---|---|---|
| baseline | 0.86 | 28.7 |
| lateral reward=True | 0.827 | 27.4 |
| speed_reward=0.12, success_reward=12.0 | 0.782 | 26.87 |
| speed_reward=0.15, success_reward=12.0 | 0.79 | 26.57 |
| speed_reward=0.18, success_reward=15.0, penalties=7.0 | 0.742 | 28.1 |
| speed_reward=0.20 | 0.73 | 27 |
| CoPO, baseline | 0.967 | 33.6 |
| CoPO, speed_reward=0.15, success_reward=12.0 | 0.905 | 31.3 |
| Success rate | Total running time (s) | |
|---|---|---|
| baseline | 0.814 | 15.97 |
| lateral reward=True | 0.77 | 15.64 |
| speed_reward=0.12, success_reward=12.0 | 0.64 | 15.87 |
| speed_reward=0.15, success_reward=12.0 | 0.77 | 15.68 |
| speed_reward=0.18, success_reward=15.0, penalties=7.0 | 0.69 | 16.34 |
| speed_reward=0.20 | 0.725 | 15.43 |
| CoPO, baseline | 0.961 | 18.3 |
| CoPO, speed_reward=0.15, success_reward=12.0 | 0.913 | 16.76 |
Generalizability to other environments
We also tried to test the generalizability of our best model trained with IPPO in roundabout environment (speed reward=0.15 and success_reward=12.0) on the intersection environment. The success rate is only 0.335, which means the trained model does not have good generalizability in a different environment. Fig 9 is a visualization of the test result, where vehicles have very high probability to run into a crash.
Discussion and Comparison
From Table 1, Table 2 and Table 3, we can see that speed_reward=0.15 and success_reward=12.0 is the best parameter configuration among the models with IPPO. This has shown that increasing the speed reward can speed up the agents and increasing the success reward simultaneously can retain the safety to a large extent. Fig 10 is the visualization of the model with speed_reward=0.15 and success_reward=12.0. Again, this is our best model and the visualization makes sense.
From Table 1, Table 2 and Table 3, we can see that when there are fewer agents in the environment, the success rate will increase noticeably with less total running time. However, when there are too few vehicles, such as only 10 agents, the car may be too fast and it is easy for them to crash and run out of the road and the success rate may witness a decrease.
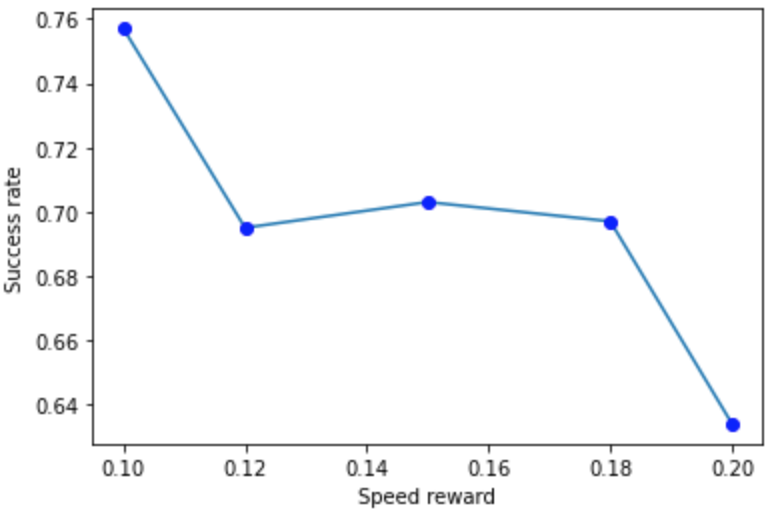
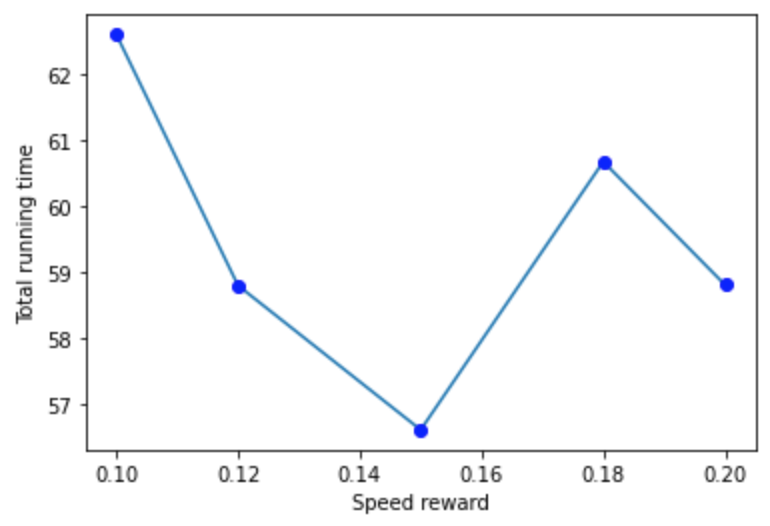
Fig 11 shows the relationship between speed reward and success rate. Speed reward and success rate are inversely proportional to each other and thus it is important to keep a balance between speed reward and safety. However, increasing the speed reward helps shrink the running time (as shown in Fig 12).
In the test of generalizability, it has shown that the parameter configuration speed_reward=0.15 and success_reward=12.0 can be used to train with other algorithms to speed up agents, since it worked on CoPO by decreasing the total running time from 84.36 seconds to 75.3 seconds while only dropping success rate from 0.802 to 0.7516. It is a very acceptable trade-off. In general, CoPO is an optimal algorithm that has very high success rate and safety, but very slow traffic. We can attemp more parameter configurations with higher speed reward to speed up agents.
When it comes to generalizability to other environments, it has shown very poor generalizability among different environments, which means a model trained on one environment performs not well on other environments. We think this is because the model need to learn information specific to the target environment in order to drive safely. However, we believe the parameter configuration speed_reward=0.15 and success_reward=12.0 can also be applied to the training of other environments and generate good performance. This experiment can be conducted in the future.
Conclusion
In this project, with the objective to speed up agents with keeping the same safety, we dived into different algorithms (IPPO and CoPO) and explored relationship between different hyperparameters in reward function. IPPO algorithm and roundabout environment are firstly researched and we found that with lateral reward used, we could speed up the environment while keeping the almost the same success rate. We also found that, by increasing the speed reward to 0.15 and the success reward to 12.0, the total running time could be minimized with tolerable drop on success rate, which is our optimal experiment result. In addition, we tested the parameter configuration speed_reward=0.15 and success_reward=12.0 on CoPO and it turned out that the total running time decreased greatly compared to the CoPO baseline. In terms of generalizability, when a well-trained model on one environment(e.g roundabout) is applied to other environment(e.g intersect), the success rate is very low, which has shown very poor generalizability among different environments.
Future work
In the future, we would like to:
- Try different parameter configurations for all multi-agent reinforcement learning algorithms to continue maximizing speed while keeping relatively high safety in the setting of one environment.
- Test if one parameter configuration that works best in one algorithm can also works best in other algorithms.
- Find the best parameter configurations to speed up agents on all the environments (train with all the environments at once).
- Modify reward function and append another reward factor if possible with the consideration of speed-safety relationship to further improve the speeding up process.
Record video
The recorded video can be found here.
Relevant Papers
[1] Li, Quanyi, et al. “MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning.” IEEE transactions on pattern analysis and machine intelligence (2022).
[2] Aldape, Pablo, and Samuel Sowell. “Reinforcement Learning for a Simple Racing Game.” Stanford, 2018.
[3] Remonda, Adrian, et al. “Formula RL: Deep Reinforcement Learning for Autonomous Racing using Telemetry Data.” CoRR, abs/2104.11106, 2021.
[4] D. Isele, A. Nakhaei and K. Fujimura, “Safe Reinforcement Learning on Autonomous Vehicles,” 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 1-6, doi: 10.1109/IROS.2018.8593420.
[5] Berkenkamp F, Turchetta M, Schoellig A, et al. Safe model-based reinforcement learning with stability guarantees[J]. Advances in neural information processing systems, 2017, 30.
[6]Peng Z, Li Q, Hui K M, et al. Learning to simulate self-driven particles system with coordinated policy optimization[J]. Advances in Neural Information Processing Systems, 2021, 34: 10784-10797.