Optimization sum-up time-consuming for multi-agents
“How long will agents stay in the traffic jam?” is one of the curious questions in autonomous driving that agents care about. In real-life, divers can know the driving map ahead or during their drives using Google Maps. However, some cars might be broken or have a car crash in the middle of the round which will occupy one or more lanes which is unexpected by the later drivers passing by. Metadrive can simulate and visualize multi-agent driving behaviors under different complex road scenarios. By using Reinforcement Learning knowledge, we can learn the traffic problem and get better solutions.
- Motivation
- Problem definition
- Potential Environment
- Algorithms
- Qualitative and quantitative experiments
- Future work
- Youtube Presentation
- Relevant Papers
Motivation
Reinforcement learning is a powerful data-driven control method in autonomous driving tasks. In the real world, many traffic scenarios may cause traffic jams. It is mainly because many cars are crossing the same complicated roads, such as bottlenecks, roundabouts, intersections, parking lots, toll gates, etc. How to get through these situations much faster remains a real problem for each driver. Currently, metadrive can simulate and visualize multi-agent driving behaviors under different complex road scenarios. If reinforcement learning could train the multi-agent better, the result may somewhat solve more real-life traffic problems. In this project, we are focusing on the bottleneck problem. In real-life, divers can know the driving map ahead or during their drives using Google Maps. However, some cars might be broken or have a car crash in the middle of the round which will occupy one or more lanes which is unexpected by the later drivers passing by. It is much similar to the bottleneck scenario. Current driving mapping can only notify the driver there is a traffic problem ahead (using the red line for notification) but cannot tell the driver which action to take. Reinforcement learning could generate policy functions under the environment and take actions to maximize the rewards.
Problem definition
Under muti-agent scenarios, cars are involved in both cooperation and competition environments. On the one side, cars need to cooperate with others so that the car flow can get through the road quicker; on the other side, each car has its self-benefits to achieve. In our driving case, it is more similar to mixed-motive Reinforcement Learning with both cooperation and competition. The cars in the environment need to Our goal for this project is to speed up the cars to let the multi-agents pass the bottleneck road much faster. Although speeding up velocity will cause crashes to increase, we still desire the whole environment to have a higher reward.
Potential Environment
MetaDrive with multi-agents at the highway.
Algorithms
Coordinated Policy Optimization (CoPo) [https://arxiv.org/abs/2110.13827] is an algorithm based on metadrive simulator. It incorporates social psychology principles to learn neural controllers for Self Driven Particles (SDP). In an SDP system, each agent pursues its own goal and constantly changes its cooperative or competitive behaviors with its nearby agents. Under SDP, CoPo introduces the Local Coordination Factor (LCF) that enables local coordination in the optimization process. Global coordination enables the automatic search for the best LCF distribution to improve population efficiency.
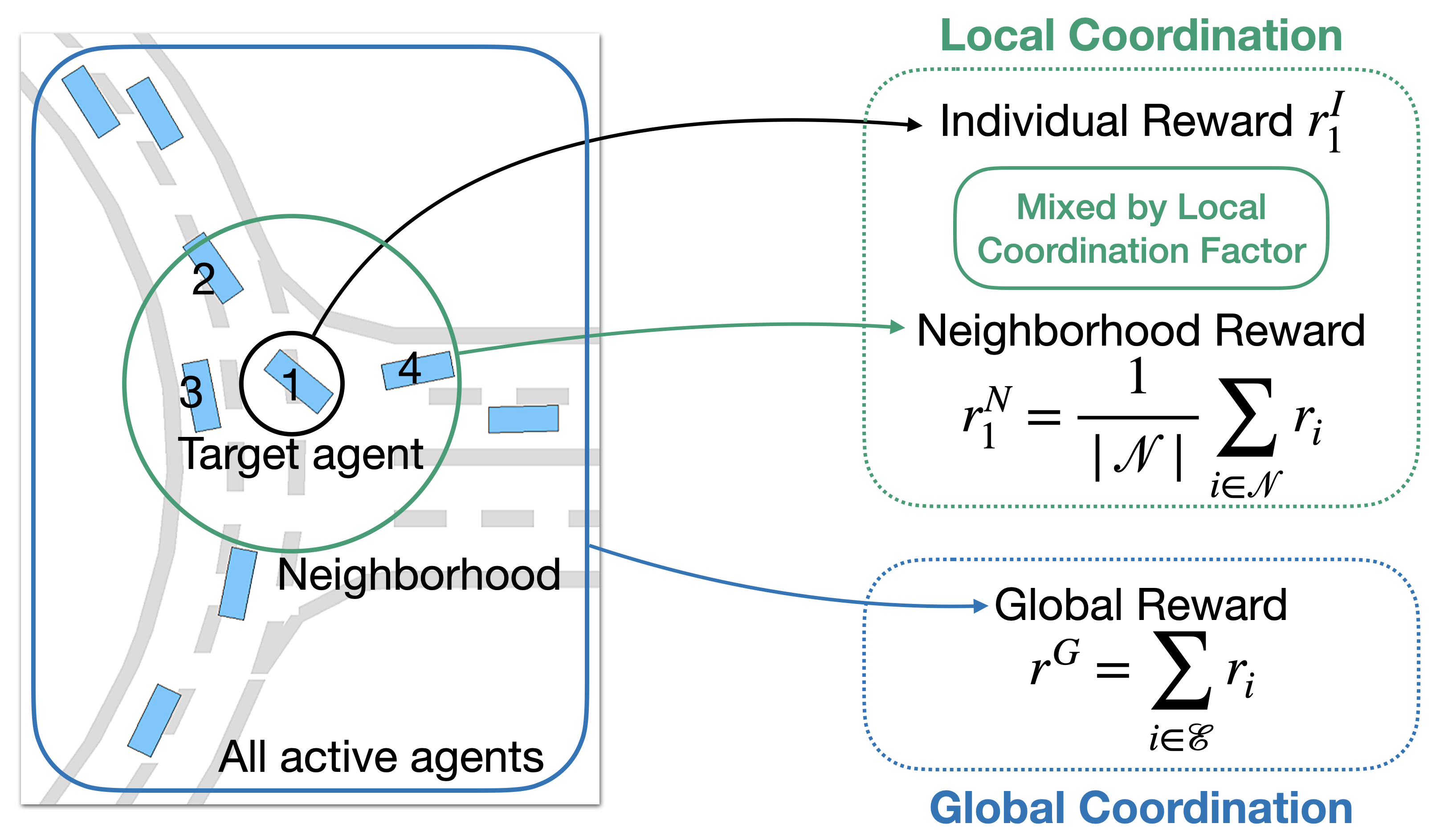
Independent PPO (IPPO) [https://arxiv.org/abs/2011.09533 4] is a form of independent learning in which each agent simply estimates its local value function. The target agent gets its individual reward and the neighborhood reward is the mean of the summation of all target agent neighbor’s rewards. In this project, we are focusing on using IPPO to let each agent maximize the total local reward (i.e. neighbors’ and own reward). To balance local reward and global reward, we set neighbors’ distance to 5000 where 10 could maximize the total local reward and 10000 will be fully cooperative.
Qualitative and quantitative experiments
To encourage agents to speed up, we increase the speed reward from default 0.1 to 0.15 so that the agent could learn from the reward function. Since speeding up may cause more crashes, we still increase the success reward from default 10.0 to 15.0. By looking into the neighbors distance, we want to find a balance between local and global rewards. Therefore, we set neighbors distance=5000. During the training, we can see that speed has a huge impact on a crash.
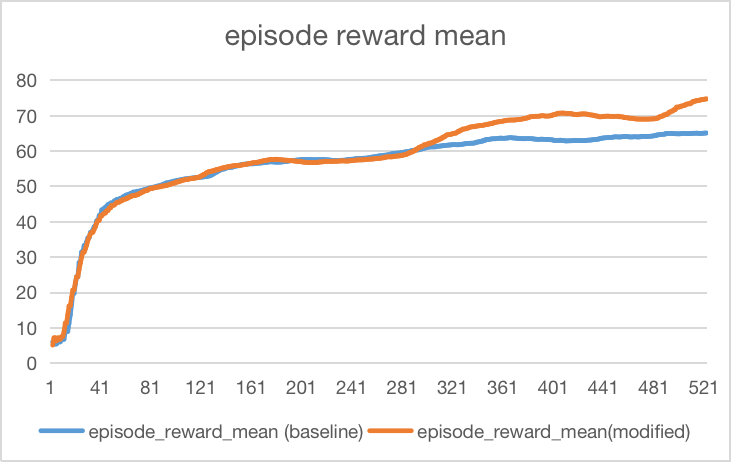
We can see in the final graph, the episode reward mean is almost similar to the beginning. However, when time goes longer, the episode reward mean is greater than the baseline. This shows that adding neighbor distance between local maximization (10) and global maximization (100) would help to increase the mean reward for each episode.
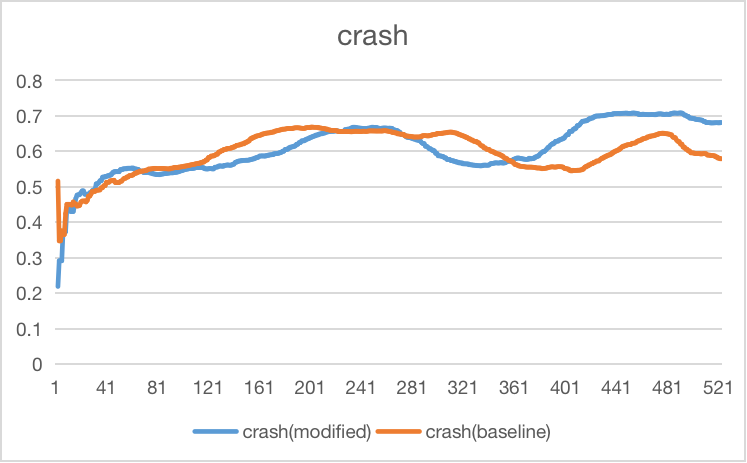
Since we increase the speed, we can assume that the crash will increase. Compared with the crash baseline for bottleneck, the crashes are not increasing dramatically. It is because we have increased the neighboring distance that can lower crashes.
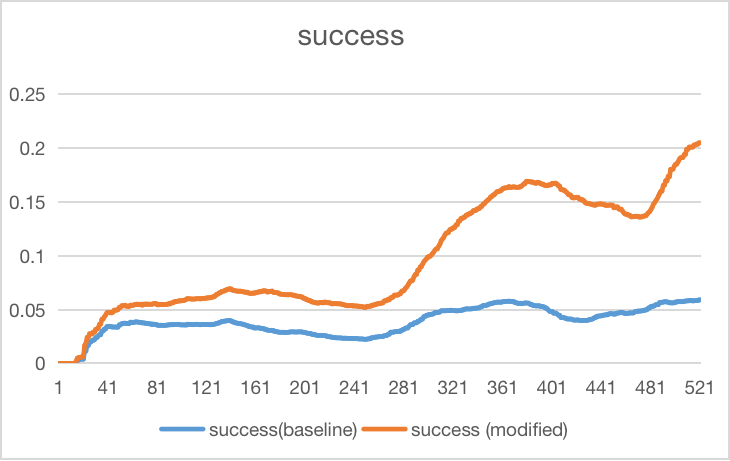
As we increase the success reward during training, the success has increased compared to the baseline bottleneck case. Since we add success rewards, it only adds when the train is a success.
Future work
Due to the memory and computational resources, we are currently only experimenting with the bottleneck environment with IPPO method. In the future, we desire to conduct more experiments on different multi-agent scenarios and use different learning methods. Currently, we haven’t installed the argoverse-api repo, so we can only measure it in metric. In the future, we are going to look at visualization, and make improvements on optimization on achieving better rewards.
Youtube Presentation
Relevant Papers
[1] Panait, L., & Luke, S. (2005). Cooperative multi-agent learning: The state of the art. Autonomous Agents and Multi-Agent Systems, 11(3), 387-434. doi:10.1007/s10458-005-2631-2
[2] Tan, M. (1993). Multi-agent reinforcement learning: Independent vs. Cooperative Agents. Machine Learning Proceedings 1993, 330-337. doi:10.1016/b978-1-55860-307-3.50049-6
[3] Yu, C., Velu, A., Vinitsky, E., Gao, J., Wang, Y., Bayen, A., & Wu, Y. (2022, November 4). The surprising effectiveness of PPO in Cooperative, multi-agent games. arXiv.org. Retrieved November 13, 2022, from https://arxiv.org/abs/2103.01955
[4] Zemzem, W., & Tagina, M. (2017). Multi-agent coordination using reinforcement learning with a relay agent. Proceedings of the 19th International Conference on Enterprise Information Systems. doi:10.5220/0006327305370545
[5] Christian Schroeder, et al. “Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge?” https://doi.org/10.48550/arXiv.2011.09533
[6] Peng, Zhenghao, et al. “Learning to simulate self-driven particles system with coordinated policy optimization.” Advances in Neural Information Processing Systems 34 (2021): 10784-10797. https://doi.org/10.48550/arXiv.2110.13827
[7] Li, Quanyi, et al. “Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.” IEEE transactions on pattern analysis and machine intelligence (2022). https://doi.org/10.48550/arXiv.2109.12674