Reinforcement Learning in Finance/Trading
In this project, we are aiming to apply reinforcement learning techniques on real finance market data. To start, we would adapt the OpenBB Terminal environment and begin with stock market data. By using OpenBB, we are interested in analyze the real-world finance data and discover how reinforcement learning can be used to predict the market. During the initial stage, we would reproduce the results from the contributors. Afterwards, we would love to explore the effectiveness the system has on various data we gather.
- Introduction Video
- Motivation
- Problem Definition
- Algorithms
- Experiment results
- Conclusion
- Discussion
- Future Works
- References
Introduction Video
Motivation
During the topic selection process, we realized that the stock market is an area where we not only can apply our reinforcement learning knowledge but also a topic that can last a long period of time, even after this course ends. The idea of turning our technical knowledge into a potential monetary value is astonishing to us. Then, we were introduced to the OpenBB Terminal platform to evaluate our project further. In OpenBB, there are numerous features that involve technical aspects of machine learning, artificial intelligence, deep learning, and reinforcement, and the feature that is the most attractive to us is stock forecasting. With the feature, users can see the predicted stock price of their selected stock for the upcoming days alongside the predictive plot as visualization. However, we believe that the information given by the OpenBB platform is just the starting point of our project. Since the forecasting feature only provides information about the given stock instead of suggesting actions, we decided to implement a reinforcement learning agent with the goal of maximizing profit in the stock market.
Problem Definition
In order to accomplish our goal of stock action prediction, we split our problem into two implementation components: stock price prediction and stock market interaction. First, reproducing the result from OpenBB Terminal, we would utilize a recurrent neural network (RNN) model with a Long Short Term Memory (LSTM) backbone to predict the upcoming stock price. Then, with the price prediction from the first part, we would then train a Deep Q-Learning agent to predict the action which includes buy, sell, and hold.
For the stock price prediction, we would use Mean Absolute Percentage Error (MAPE) as our measuring metric, and compare it with OpenBB’s result for quality purposes. On the other hand, the stock market interaction would be evaluated simply with the total profit generated by the agent.
Algorithms
Stock price prediction
To predict stock price, we utilize long short-term memory networks (LSTM), one of the varieties of recurrent neural networks (RNN) that is useful in time series forecasting. In RNN, the formula for calculating the current state:
\[h_{t} = f(h_{t-1}, x_{t})\], where \(h_{t}\) is the current state, \(h_{t-1}\) is the previous state, and \(x_{t}\) is the current input state. And the formula for applying the Activation Function (Φ):
\[h_{t} = Φ(W_{hh}h_{t-1}, W_{xh}x_{t})\], where \(W_{hh}\) is the weight at the recurrent neuron and \(W_{xh}\) is the weight at the input neuron. To calculate the output, we have this formula:
\[y_{t} = W_{hy}h_{t}\], where \(y_{t}\) is the output and \(W_{hy}\) is the weight at the output layer.
Training loop for RNN:
- Provide a single time step of the input \(x_{t}\) to the network
- Calculate the current state \(h_{t}\) based on the current input \(x_{t}\) and the previous state \(h_{t-1}\)
- The current state \(h_{t}\) becomes \(h_{t-1}\) for the next step (RNN can take as many time steps according to the problem)
- Gather the information from all of the time steps and calculate the final current state, then calculate the final output
- With the calculated output and the actual data, generate the error.
- Back-propagate the error to the network to update the weights
Stock market interaction
To train an agent that interacts with the stock market, we utilize Deep Q learning. In the reinforcement learning setting, the stock market is the environment, the agent decides what action to make depending on the historical stock price, the actions available for the agent are hold, buy, and sell, and the reward is the profit from buying low and selling high. The input of the network is:
\[sigmoid(x), x = [x_{0}, x_{1}, x_{2}…]\],where \(x_{i}\) is the stock price difference between two consecutive days. Other than that, the training loop and the network design are identical to the DQN algorithm.
However, based on the previous experience, we found that the agent would keep buying the stock at the beginning of the training because of the ε-greedy algorithm. Therefore, we added a restriction that the agent is not allowed to hold an amount of stock of more than 5. Also, with the given state, the agent is only allowed to make one of the actions (hold, buy, and sell). Lastly, we set the max length of the episode to 90 so that we could know how much the agent earns within the given time.
Experiment results
For the stock price prediction model, we set our long short-term memory network’s input window size to 120 and trained the model with the historical data from five different companies: Apple, Amazon, Google, Microsoft, and Meta, with the close stock prices from Jan. 1\(^{st}\), 2012 to Nov. 25\(^{th}\), 2022. 80% of the data is for training and the other 20% is for testing. To compare with the stock prediction model from OpenBB, we used the same metric (MAPE). Note that the model can only predict the near future and cannot predict the following future solely based on its previous prediction. It still needs real data (+ historical data) to maintain the accuracy.
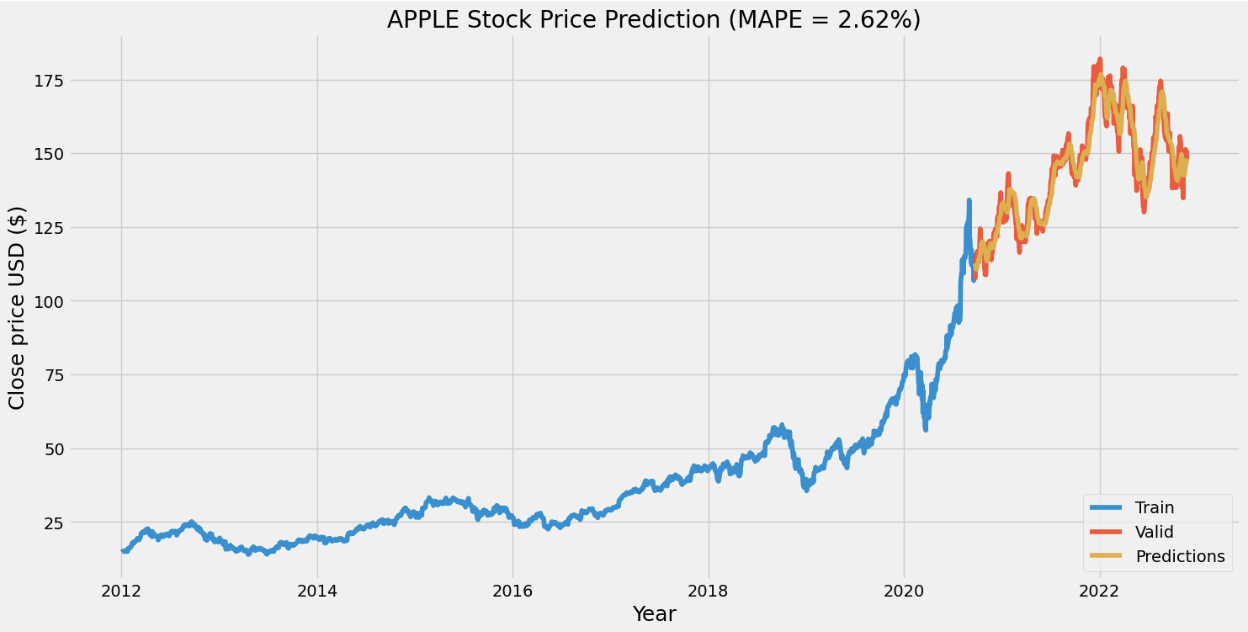
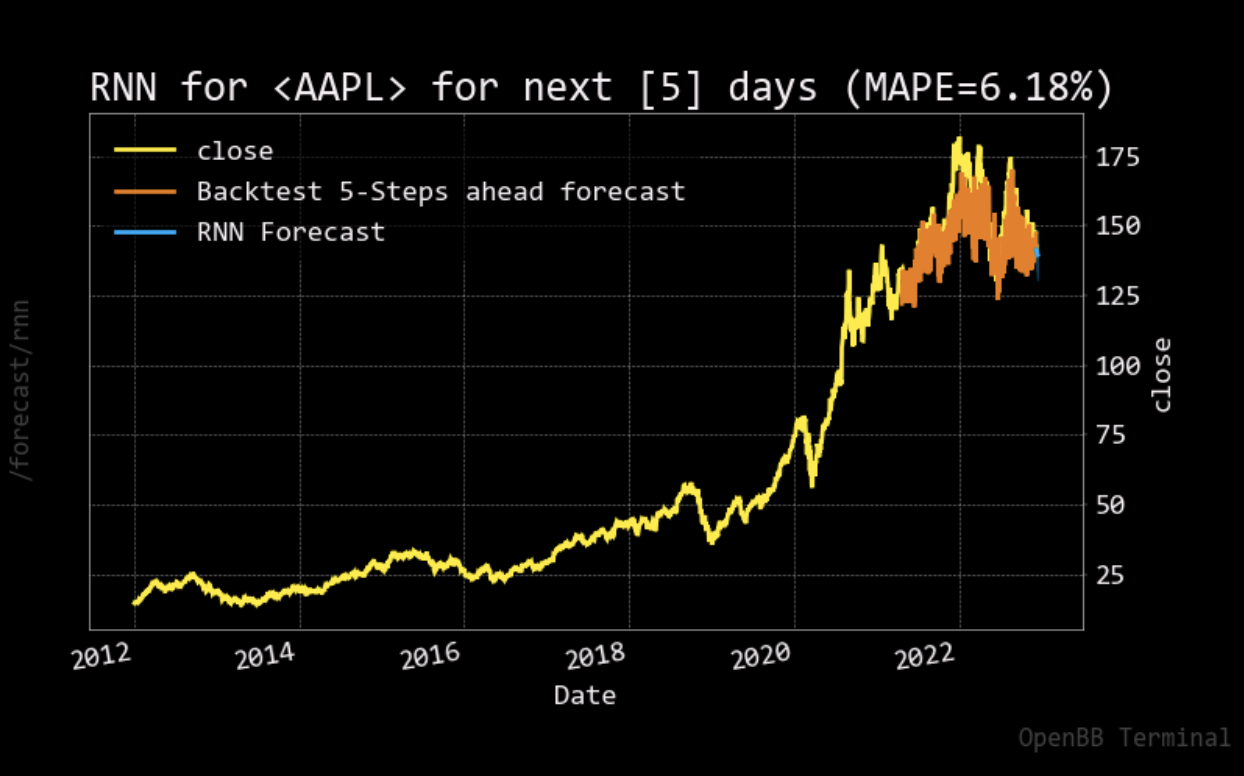
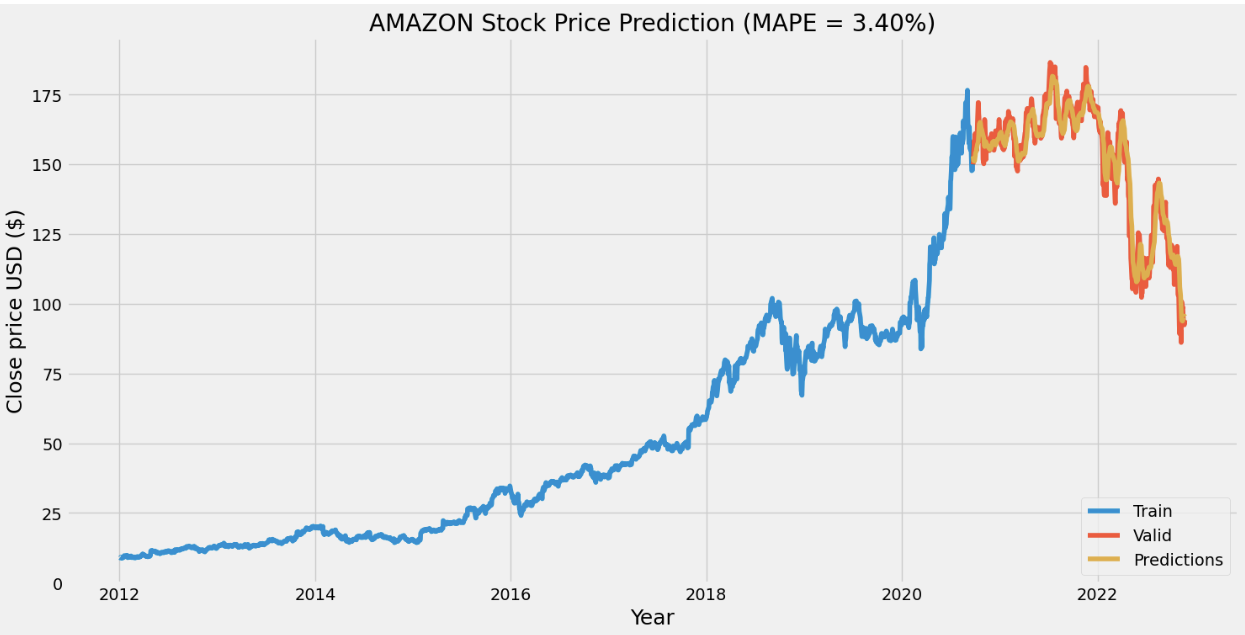
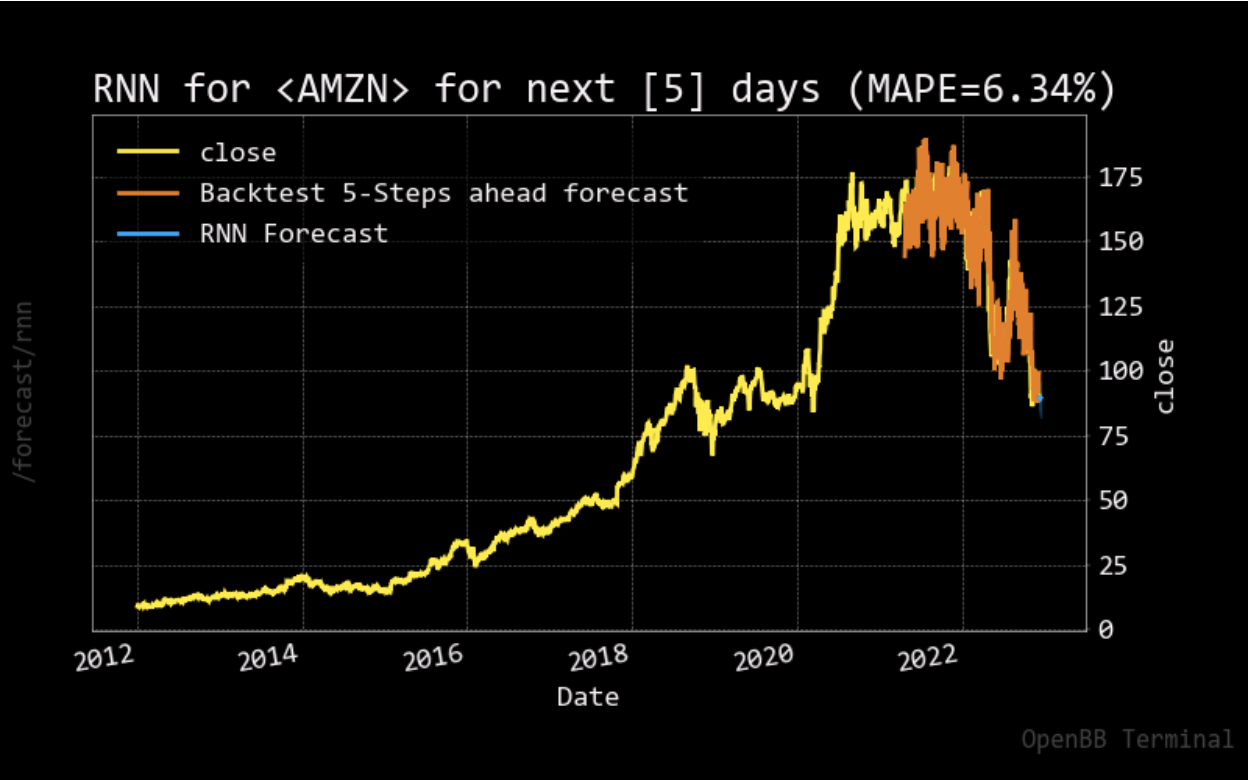
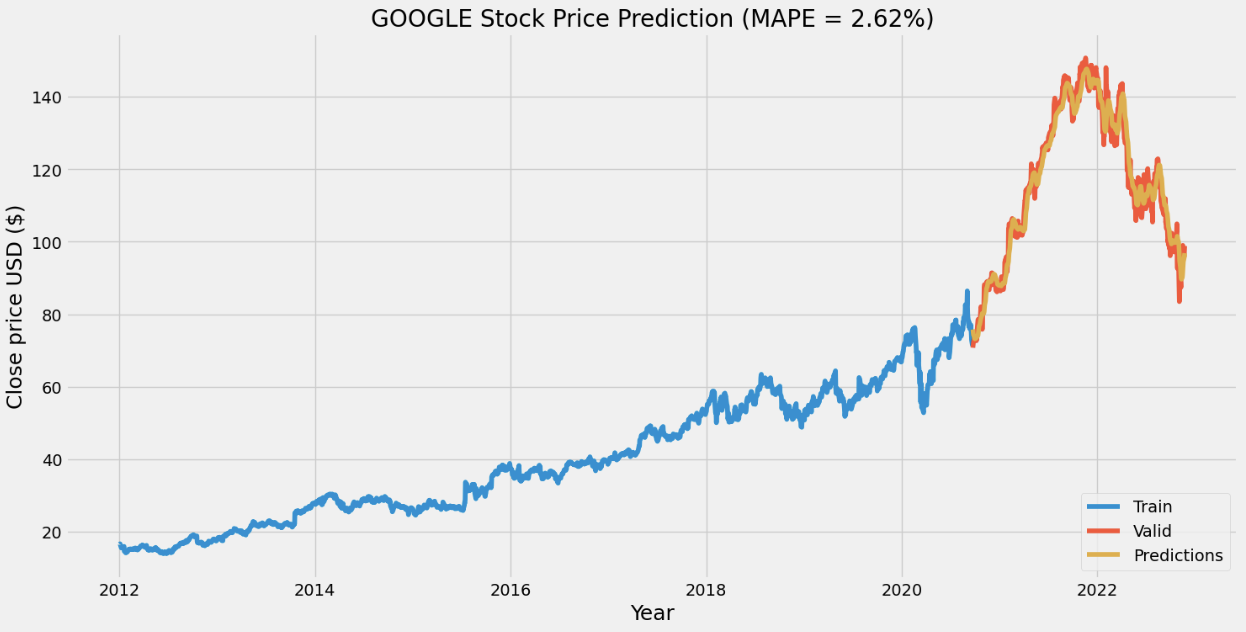
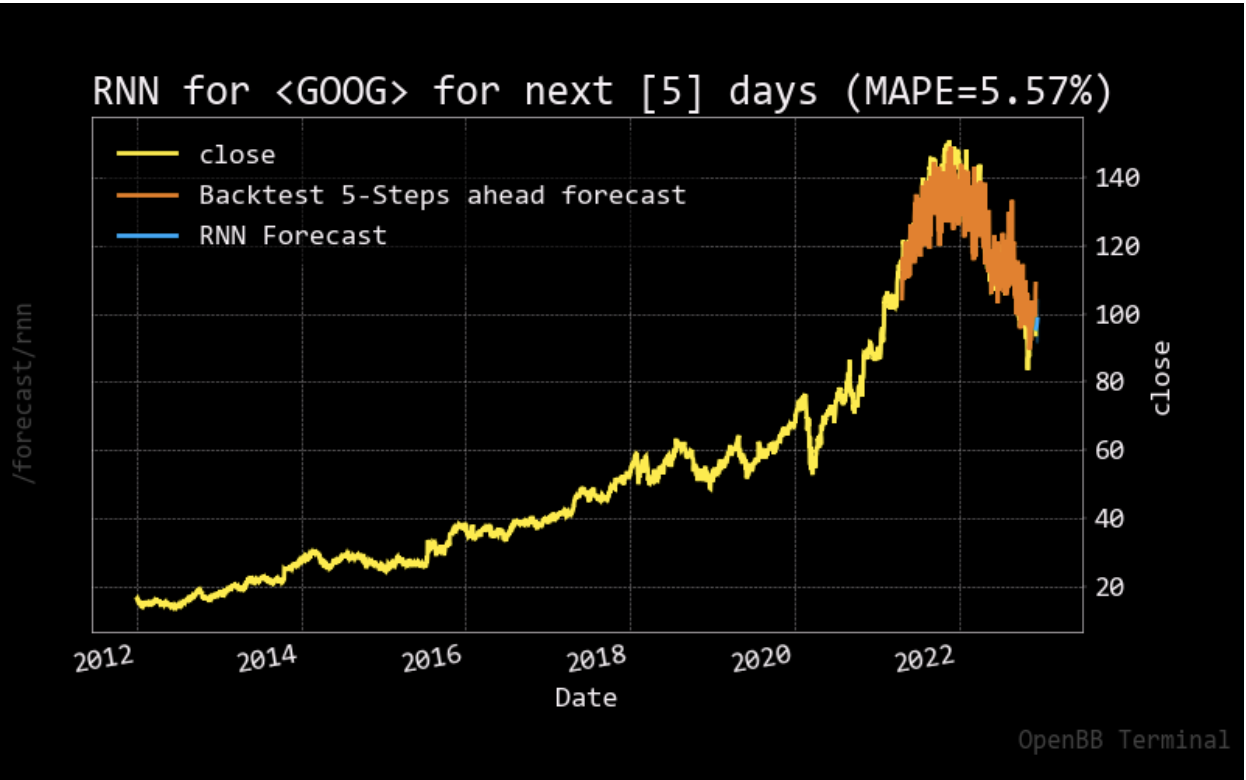
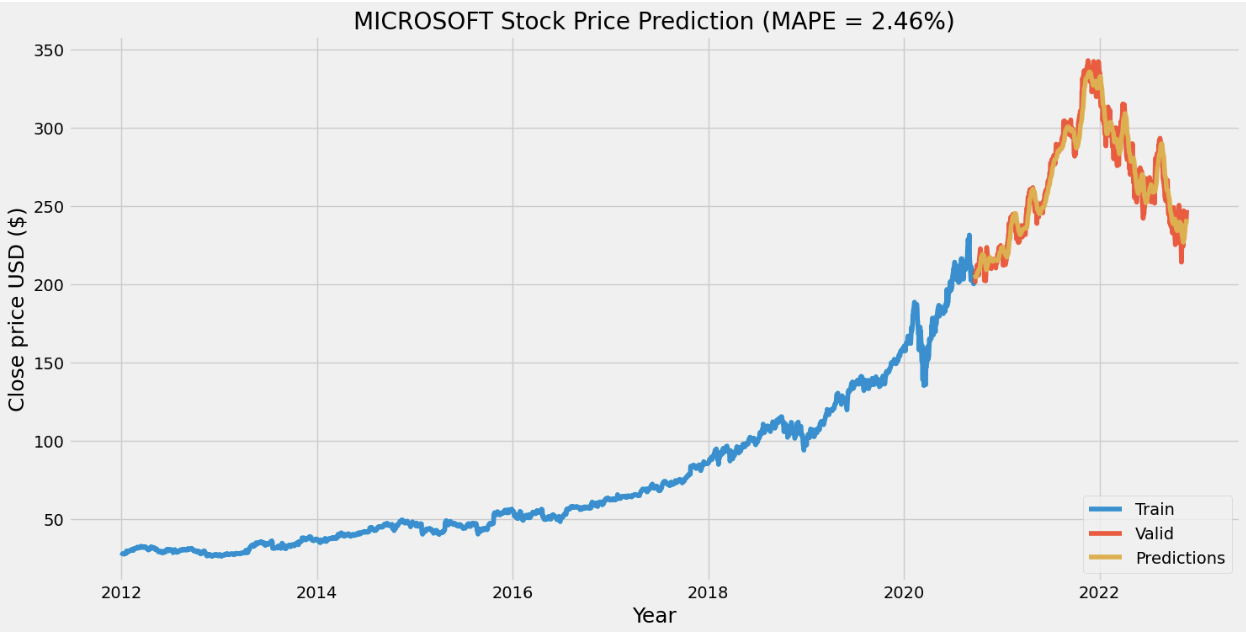
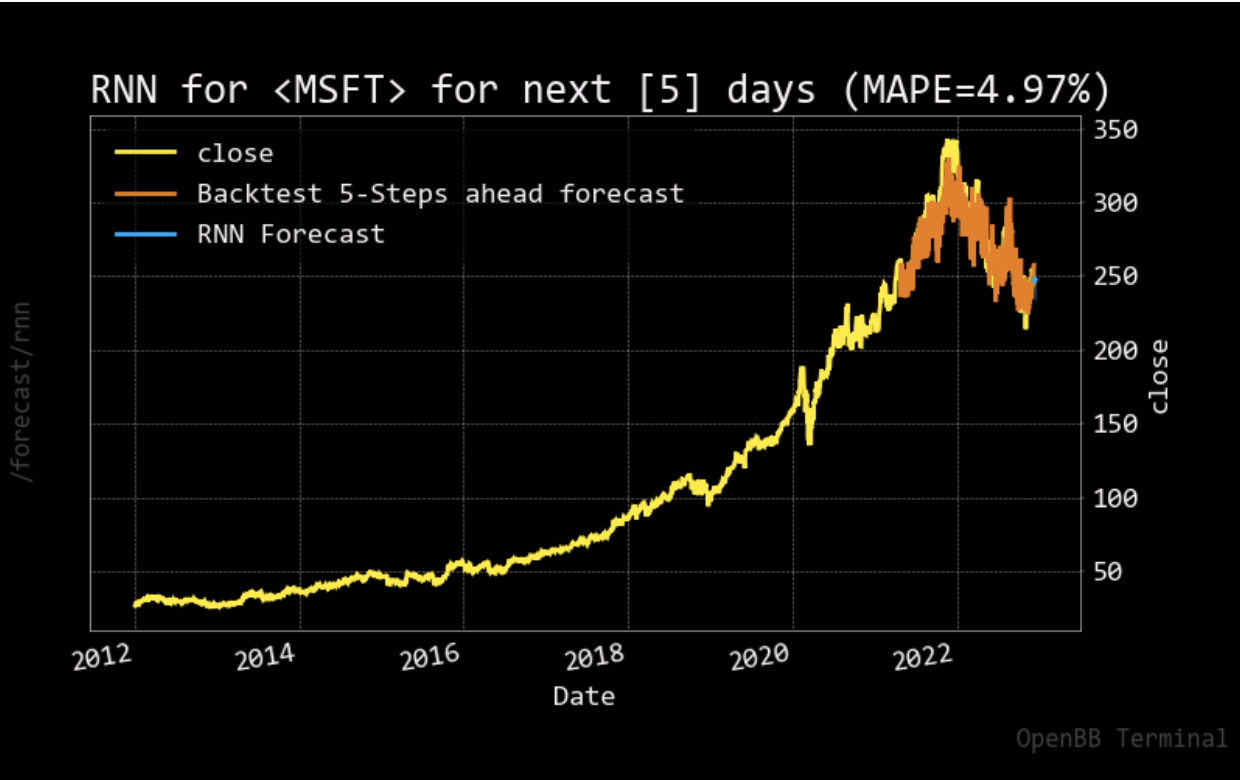
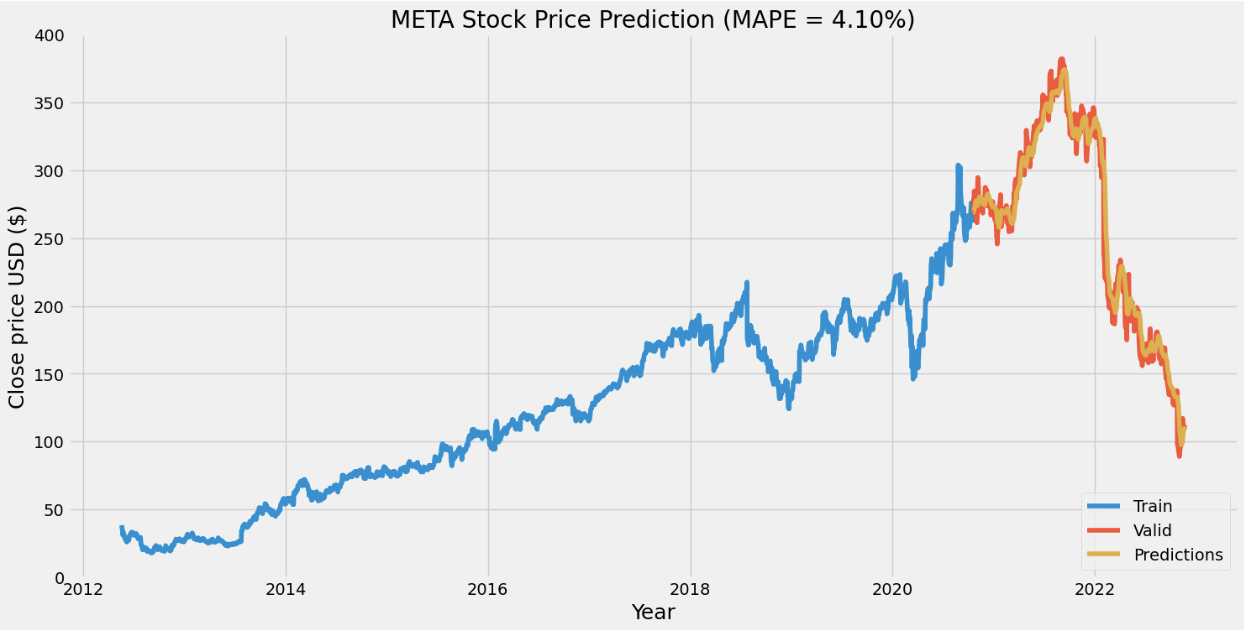
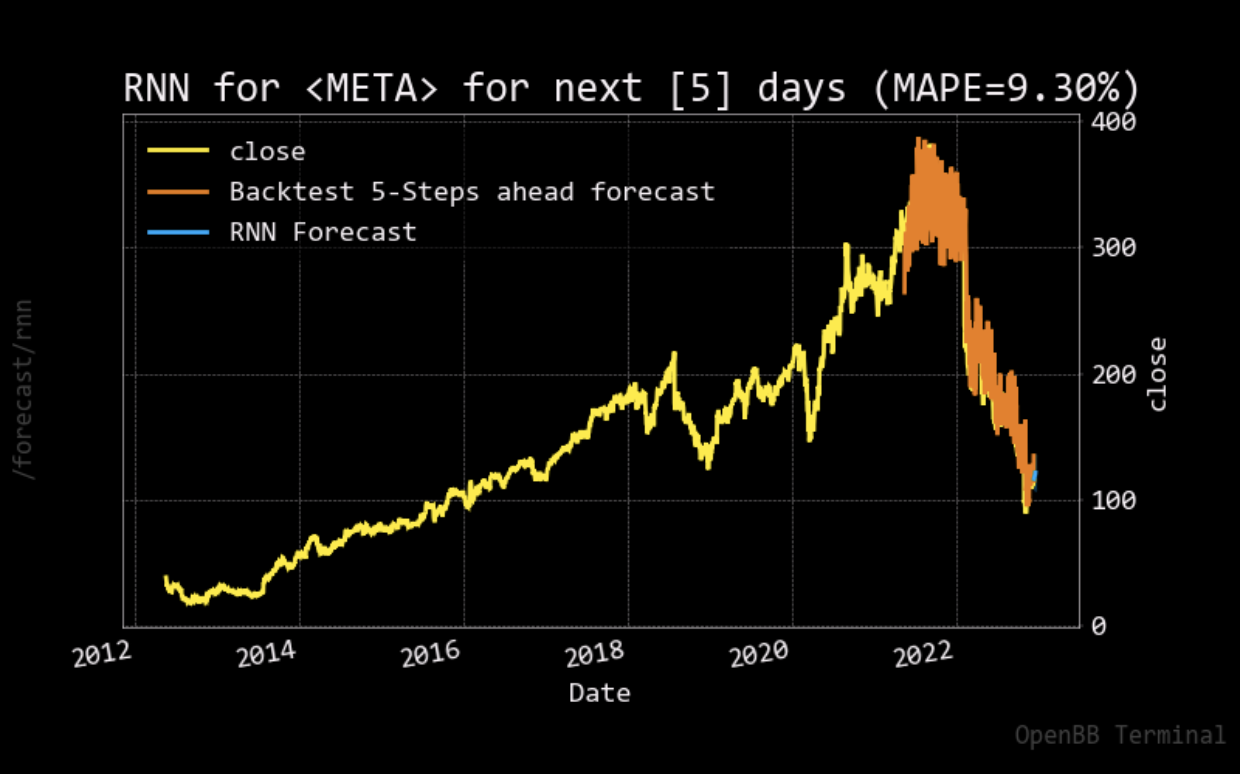
After having a predictive model, we then constructed our DQN networks. Since we wanted the prediction to affect how the agent interacts with the stock market, we did not want the window size to be too big. Otherwise, the agent only takes the historical data into account but not the prediction. Therefore, we set the window size of the deep Q learning network to 10, half for historical data and the other half for prediction. To compare if prediction helps, we also have an agent that only takes historical data as input. Next, we trained and tested our model with the same data from the same companies. The following plots show how much the agent can earn in a 90-day interval.
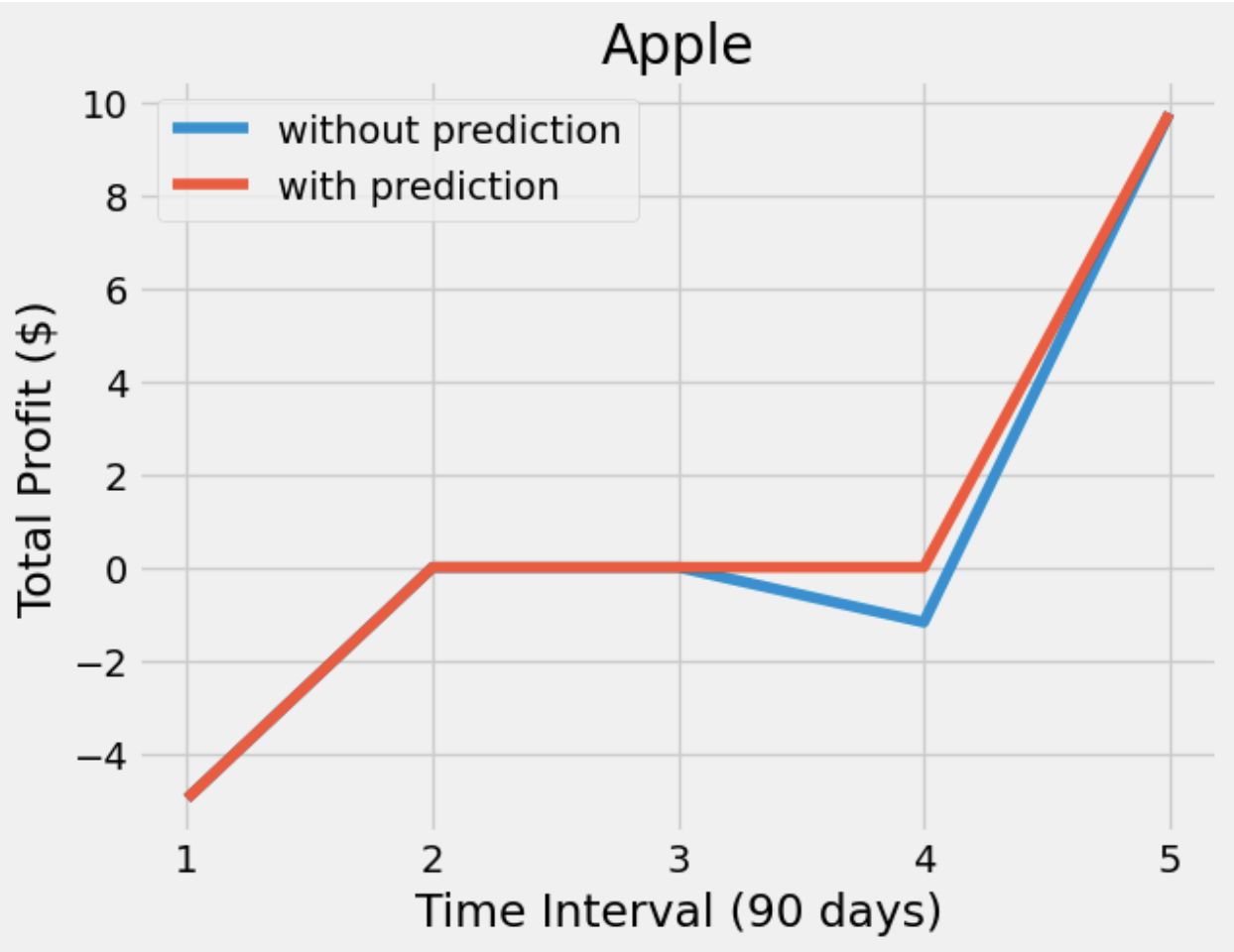
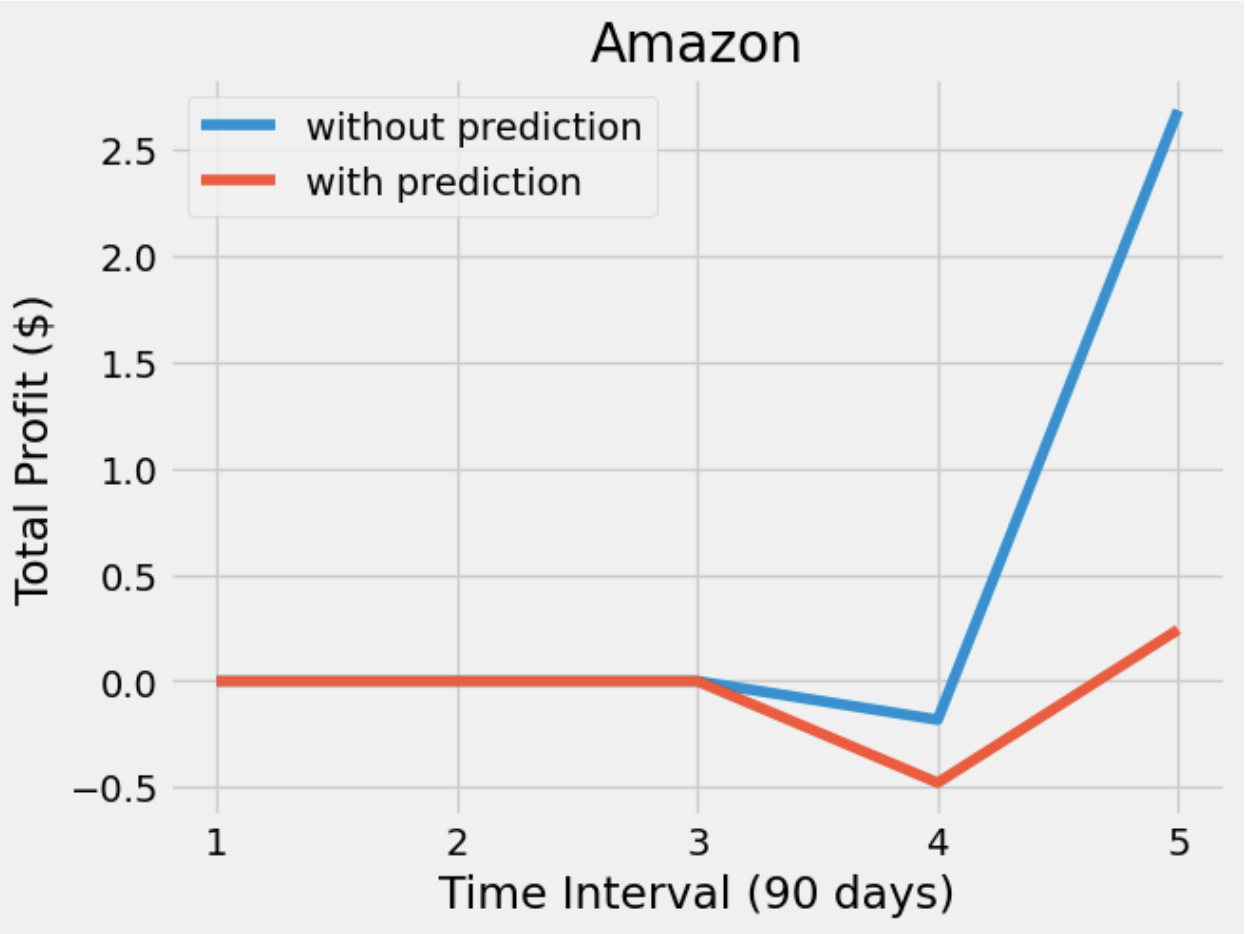
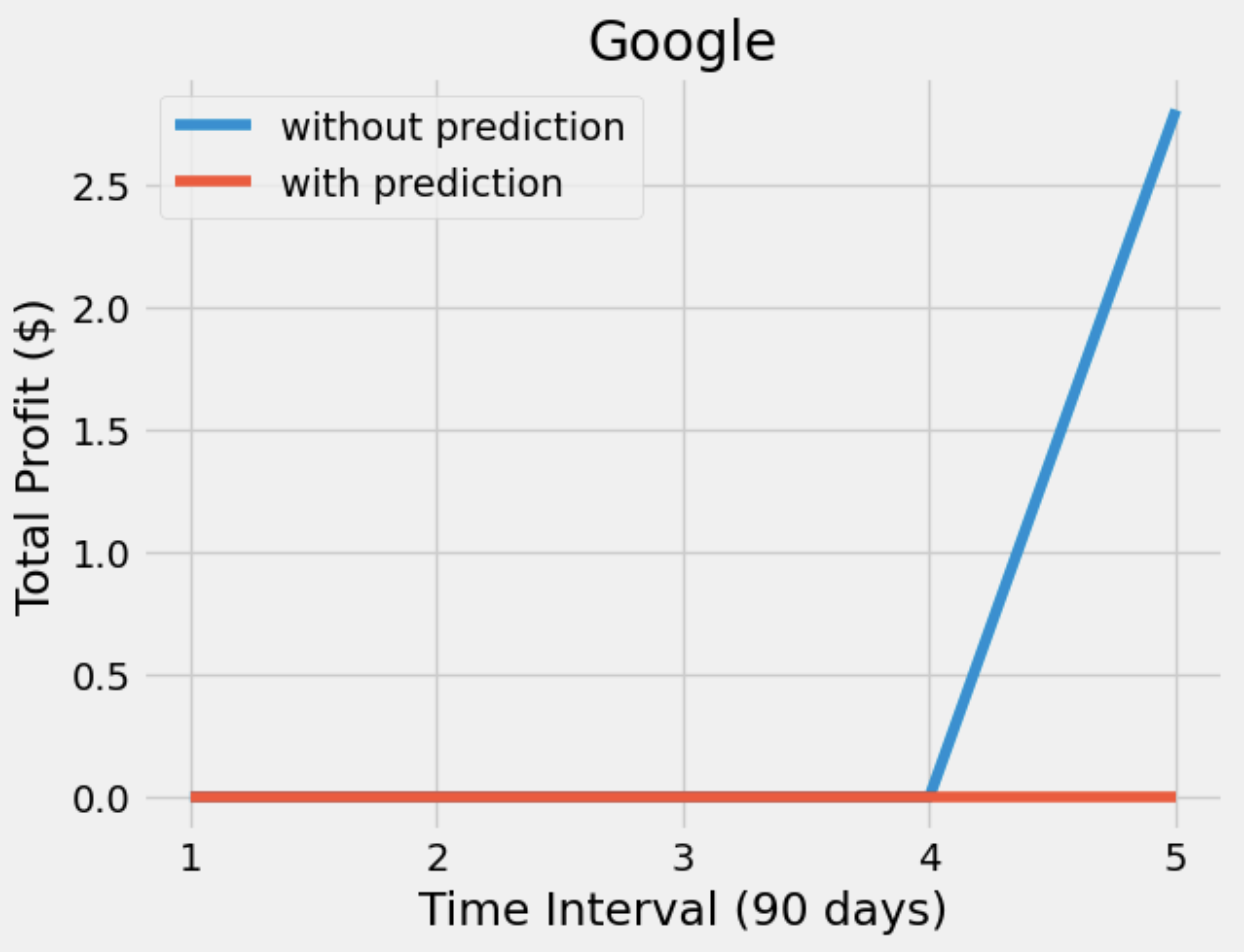
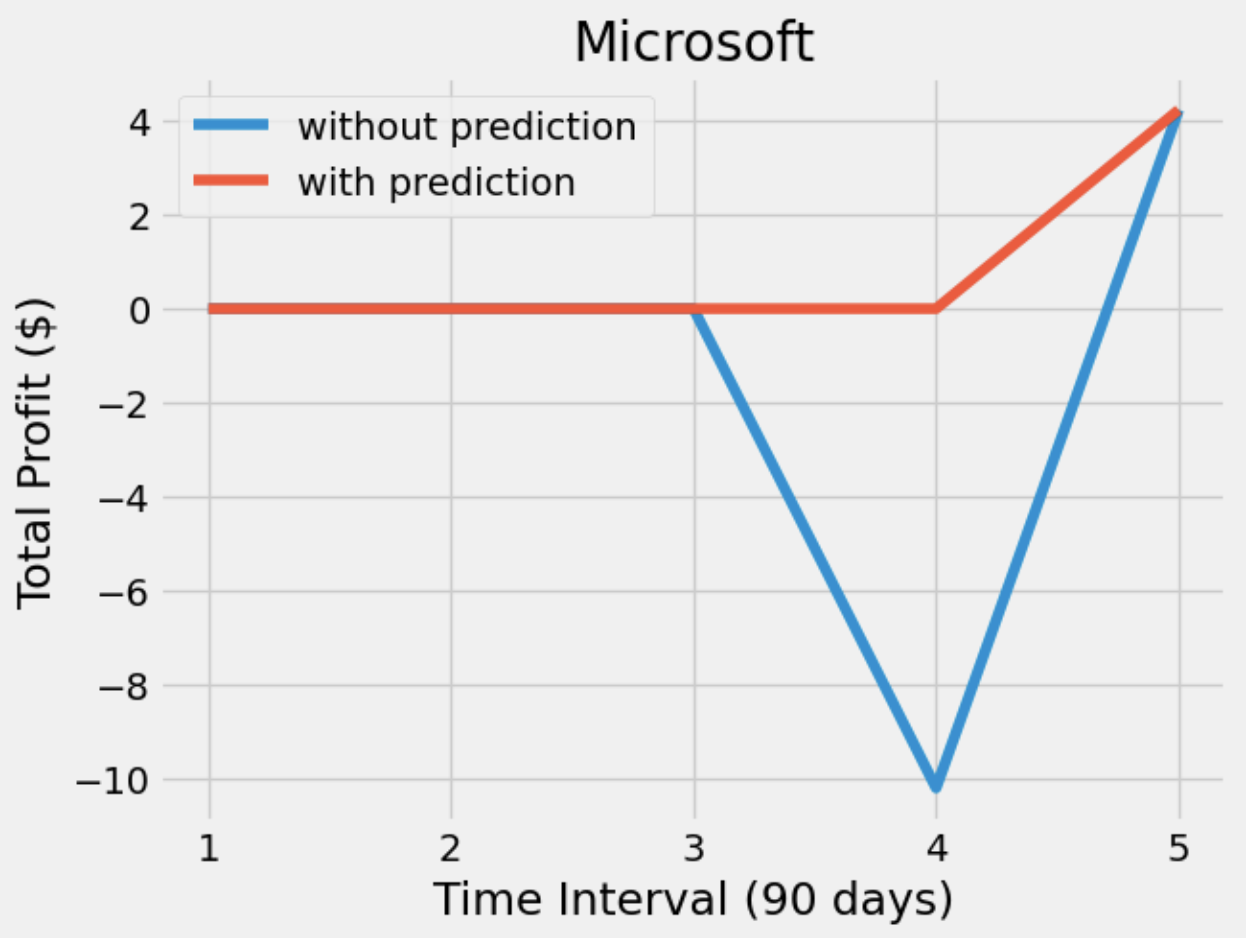
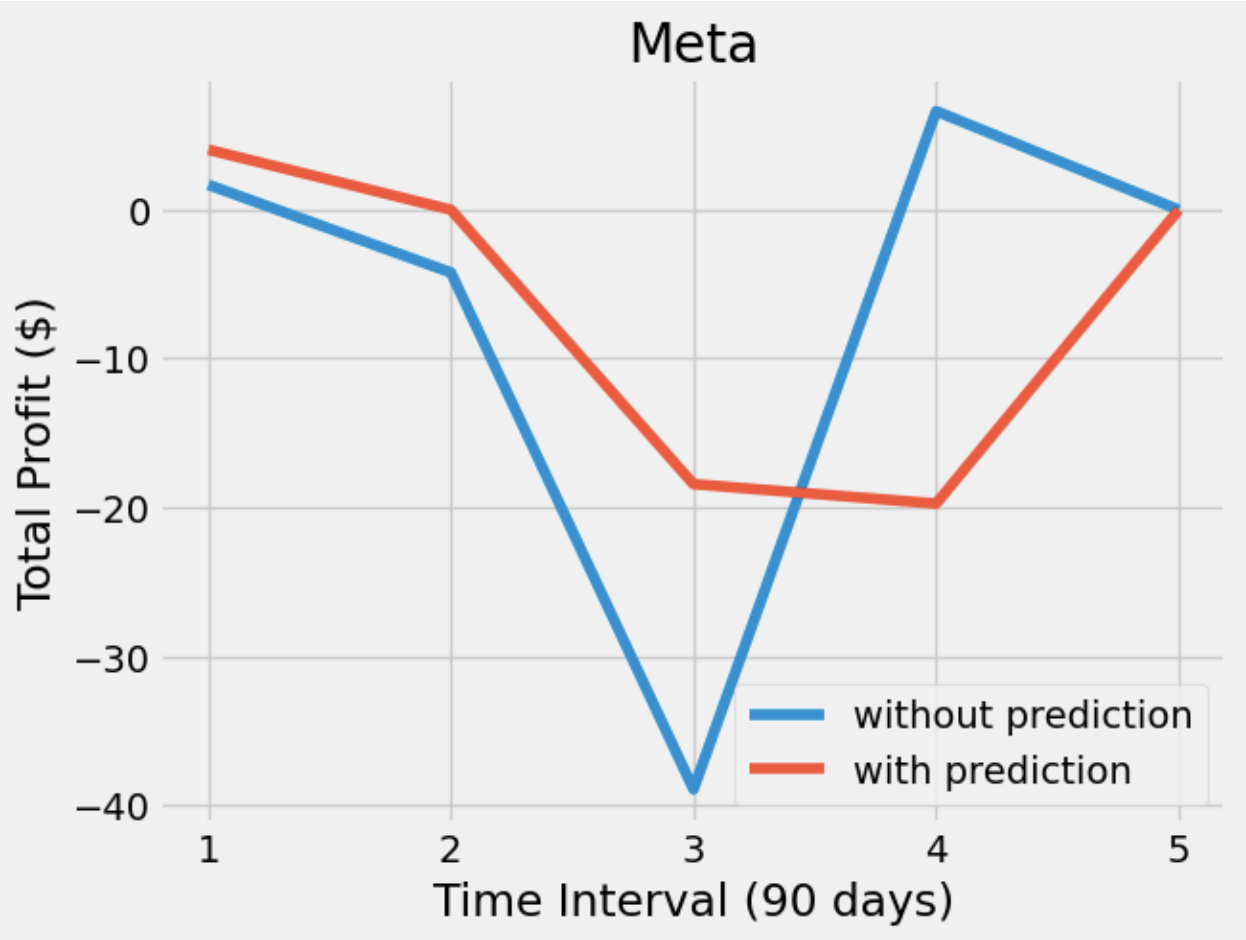
From the plots, we can see that both agents have similar profit. However, the agent with prediction is more conservative so that it is more likely to have a stable profit, meaning that it does not earn too much money but also does not lose too much money. On the other hand, the agent without prediction is willing to take actions. Sometimes it buys a stock at a higher price which may lead to it losing more money, but sometimes the action it took makes more money. Besides the difference between the agents, we also found that these agents are much more willing to hold than either buy or sell. Considering the window size and the restrictions we gave to the agents, we considered it as an odd but reasonable result.
Conclusion
- Reproduction of OpenBB forecasting model with RNN was successful, our model achieved a lower MAPE than OpenBB.
- Combining the prediction with historical data as training data for our agent.
- The agent averages a low profit or break-even.
Discussion
Based on numerous modifications and different implementations, we observed that no matter what training data was fed to the model, the “HOLD” actions way exceed the “BUY” and “SELL”. After consulting with experts in the stock market, the conclusion we received was realistic and the agent interpreted the data well. In other words, the model learned from the data that continuously buying or selling a market may not be the best way of earning profit in the stock. Before the experiment, we did anticipate the task of earning profit to be difficult, but we did not expect to have our agent reflect such a realistic result. Nevertheless, this is an interesting outcome from this project, and we should continue to explore more aspects of the market with other variations of data.
Future Works
- Include more features and parameters in the model for a more accurate prediction.
- Redefine the relationship between the reward and the actions so that the agent is encouraged to make profit.
- Try different reinforcement algorithms for more complex action combinations.
References
OpenBB Terminal https://github.com/OpenBB-finance/OpenBBTerminal
Stock Price Prediction Using Recurrent Neural Network(Artificial Intelligence) https://medium.datadriveninvestor.com/stock-price-prediction-using-recurrent-neural-network-artificial-intelligence-ffe6ac1bd344
Predicting Stock Prices using Reinforcement Learning (with Python Code!) https://www.analyticsvidhya.com/blog/2020/10/reinforcement-learning-stock-price-prediction/