Design Our Model Based on What is Provided by CoPO
The project will consist of two parts. In the first part, we will reproduce the results from Independent Policy Optimization[5], IPO, (implemented with PPO), MFPO, CL, CoPO. Fine-tuning of the models will be attempted to explore possibly better results. During the second part, we will design, implement, train, and test our own models. We plan to design our model based on what is provided by CoPO.
- Introduction
- Proposed Work
- Nov. 11 Update:
- Expected Result
- Potential Environment
- Dec. 8 Update:
- Recorded Video
- Reference
Introduction
Self-Driven Particles(SDP) are common in human society such as various categories of multi-agent systems(MAS). We will explore on a novel multi-agent reinforcement learning (MARL) method, Coordinated Policy Optimization(CoPO)[1] which has been tested that having a better performance than previous MARL methods: Curriculum Learning(CL)[2], Mean Field Policy Optimization(MFPO)[3], and Proximal Policy Optimization(PPO)[4]. The original CoPO has three rewards, Individual Reward and Neighborhood Reward as Local Coordination, and Global Reward as Global Coordination. Although the data of the results looks in a good performance, the movement of the agents are not in a human way which is conflicting with the concept of observing how human interacts. We decide to design new reward policy in order to have the same performance with better movement.
Proposed Work
The project will consists of two parts. In the first part, we will reproduce the results from Independent Policy Optimization[5], IPO, (implemented with PPO), MFPO, CL, CoPO. Fine-tuning of the models will be attempted to explore possibly better results. During the second part, we will degisn, implement, train, and test our own models. We plan to design our model based on what is provided by CoPO. Noticing in the scenarios shown in the CoPO paper that the agents frenquently makes slight turns or sometimes makes half-lane changes, we aim to eliminate these seemingly meaningless actions through additional rewards. We propose to add rewards related to the frequency of turns made by the agent. The less the agent turns, the more it gains from the added reward. One drawback of this approach would be since the agents have low incentive to maneuver themselves frequently, it could lead the environment to congestion. In order to address this issue, we add an additional reward related to the timely arrival of the agent. During training, the agent will determine the best balance between low travel time and frequent lane changes. Moreover, we could use the philosophy proposed by CoPO, neighborhood reward, to coordinate the newly added rewards.
Nov. 11 Update:
Environment
Following the installation instruction in https://github.com/decisionforce/CoPO. CUDA was also installed for better training steps. We setup the environments on a Linux matchine for training and a Windows machine for visualization.
Process
After installing the code and environment of CoPO and metadrive from github, we trained all the algorithms with seed 5000 since it takes too much time training on one seed. It is unable to train with all the seeds with greed search. The results have very small difference from the results on the paper.
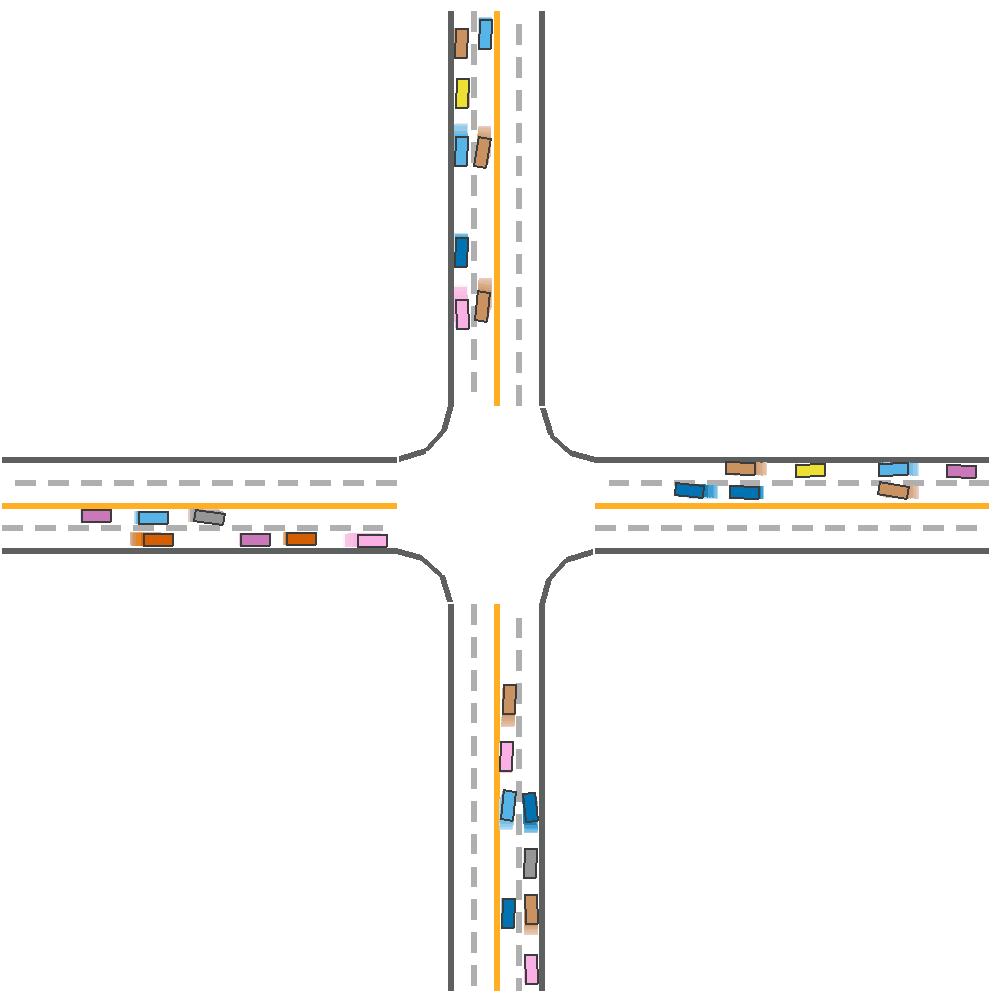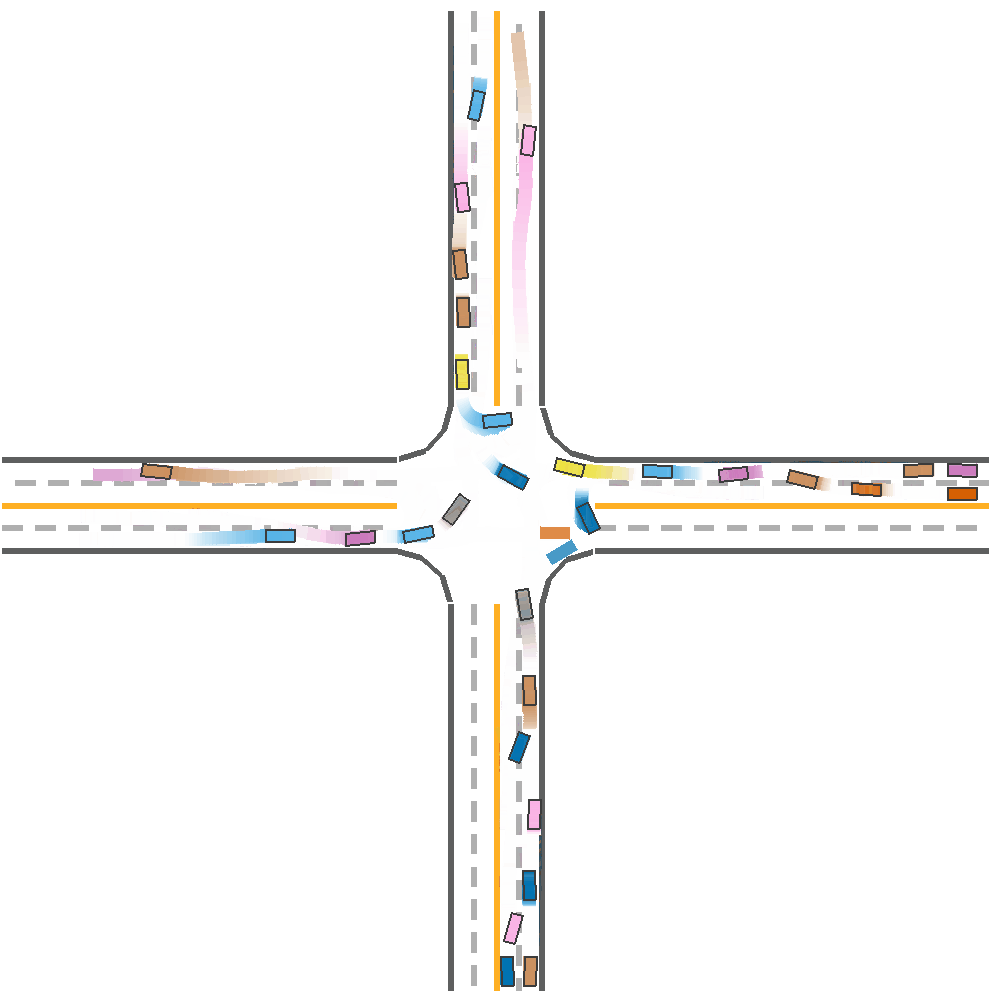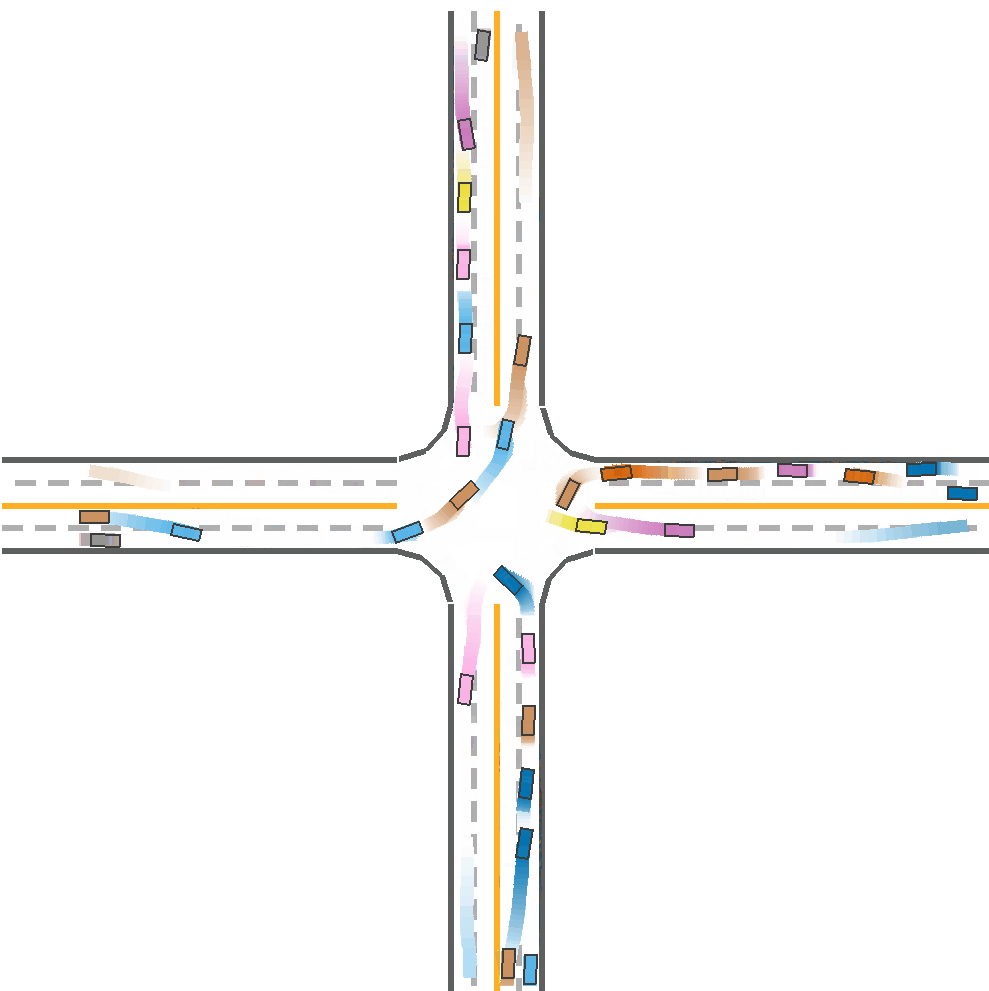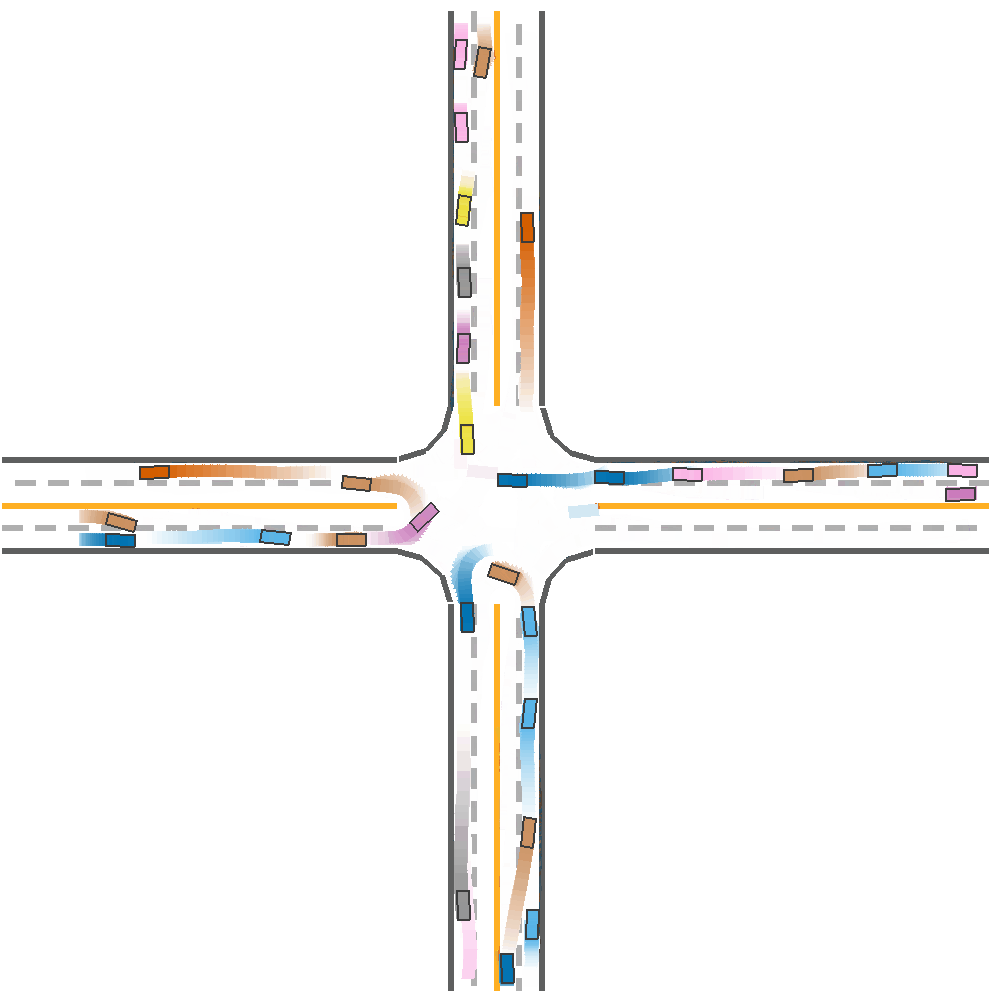
Expected Result
We will use the performance metric, triangle graph, used in the CoPO paper to discuss the expected result.
- We expect the safety of our model to be at least as good as CoPO in all scenarios, simply because less frequent lane changes would make the agents less likely to crash.
- Regarding efficiency, we also expect increase due to the fact that our models makes less meaningless maneuvers that could effect the agents’ own and potentially other agents’ efficiency.
- However, they might be a performance drop in success rate because the lack of incentive to make lane changes by the agents could lead to traffic gridlock.
Potential Environment
MetaDrive in Python

Dec. 8 Update:
Approach 1: Penalize excessive maneuvers
Implementation
As we can see in the CoPO visual evaluation in the roundabout environment, the vehicles often make unnecessary maneuvers. Thus, a natural approach to limit the maneuver is to penalize based on the magnitude of the action. We first look at the action space of the driving simulator we used, MetaDrive.
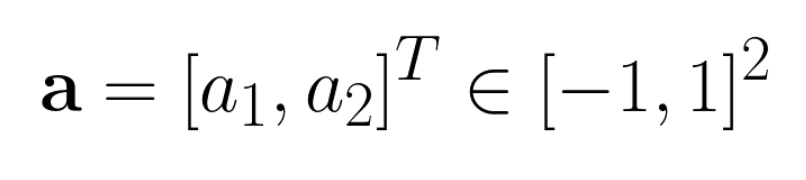
a_1 controls how the vehicle turns and a_2 controls how the vehicle accelerates and brakes. Thus, an negative reward term is formed by multiplying the norm of the action vector with a coefficient. We name the coefficient maneuver penalty coefficient. The term is negative because it serves as penalization. This term will be added to the total reward for each vehicle to fulfill the above mentioned goal.
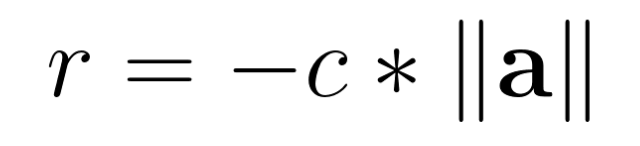
Evaluation
The modified CoPO was trained on MetaDrive Intersection environment with grid search of different maneuver coefficient. The best performaning coefficient is 0.005.
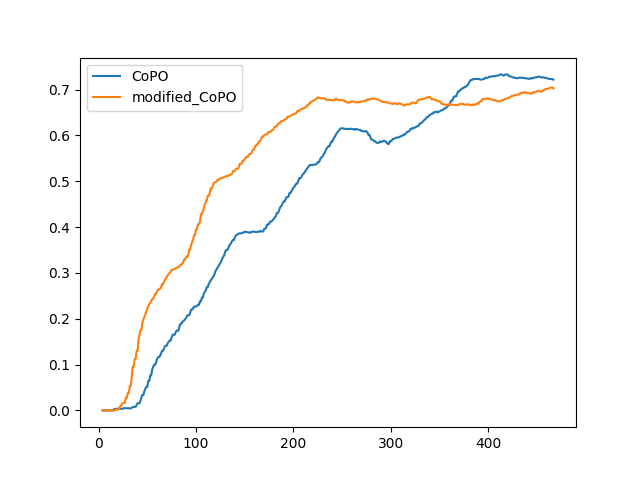
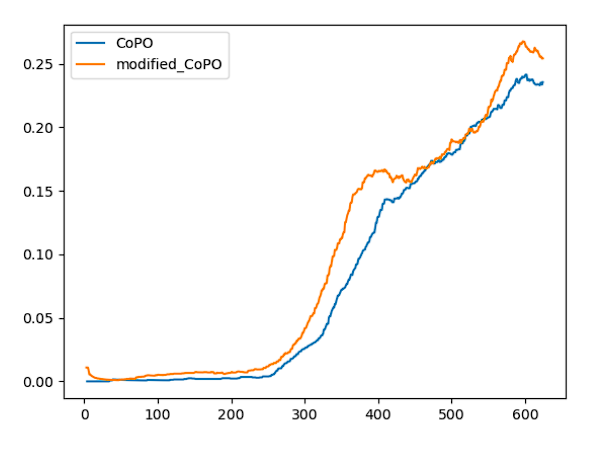
As we can see from the figure, after convergence, the performance are similar for the two algorithms. However, it seems that modified CoPO converges after than CoPO. This is an interesting behavior to investigate further.
Future plans
We will fine-tune the algorithm on more environments to evaluate its genelization capibility.
Approach 2: Penalize longer total trip time
We changed the discount factor(gamma) with time penalty(tt) by the algorithm below. The time is initially set to 10 and the gamma is always inputed as 1. Therefore, gamma will start from minimum 0.9 to maximum 1.0, as time increasing.
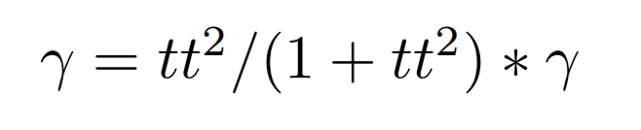
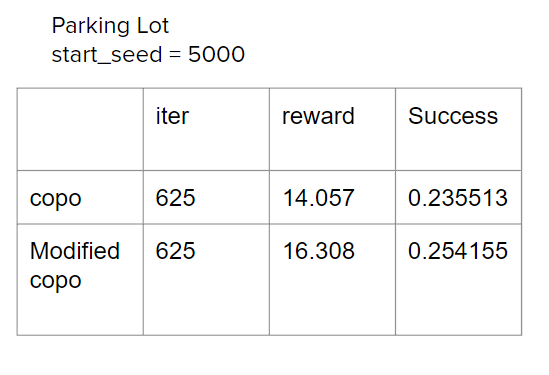
The testing environment is set to Metadrive ParkingLot with start_seed 5000. The result of our modified CoPO and orginial Copo is shown below:
Recorded Video
The link to recorded video. The password is GHW#b.j7
Reference
[1] Peng, Zhenghao, et al. “Learning to Simulate Self-Driven Particles System with Coordinated Policy Optimization.” ArXiv.org, 10 Jan. 2022.
[2] Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: A framework and survey. Journal of Machine Learning Research, 21(181):1–50, 2020.
[3] Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. In International Conference on Machine Learning, pages 5571–5580. PMLR, 2018.
[4] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[5] Christian Schroeder de Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip HS Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge? arXiv e-prints, pages arXiv–2011, 2020.