Autonomous driving based on CARLA
These years, the tech giant companies have set off a boom in the development of autonomous driving, Waymo began as the Google self-driving car project in 2009, and the Tesla Motors announced its first version of Autopilot in 2014. So our team would also like to explore the autonomous driving skills by reinforcement learning in the CALRA simulator.
- Project Proposal
- Driving Simulator Environments
- Toolkits and Libraries
- Current Progress
- Conclusion
- Future Work
- Project Timeline
- Final Presentation Update
- Team 18 Contact Info
- Reference
Project Proposal
For this project, we will train a reinforcement learning model and deliver an autonomous car simulate the real urban environment by using CARLA. Through viewing the CARLA paper Autonomous Vehicle Control in CARLA Challenge, we got interested working in the CARLA simulation for our autonomous driving cars. It is a perfect simulation for training the reinforcement learning to reach our goal. Tons of teams test their projects’ performance through the platform of CARLA. For example, a team implements the DDPG car - DDPG car-following model with real-world human driving experience in CARLA. CARLA has been developed from the ground up to support development, training, and validation of autonomous driving system.
The goal is to develop a car that can distinguish the complex urban layouts, avoid the barriers on the street and have different actions towards corresponding situations such as making a turn, slowing down and braking. We hope we can be more familiar with the usage and core structure of CARLA through this project. For accomplishing this goal, we first selected a relatively simple Q-learning model to train the agent after rendering the CARLA environment. And our task is to train the car (agent) to move from point A to point B.

Driving Simulator Environments
CARLA Basic Architecture:
CARLA is mainly divided into two modules including Server and Client. The Server is used to build the simulation world, and the Client is controlled by the user to adjust and change the simulation world.
- Server: The server side is responsible for everything related to the simulation itself: from 3D rendering cars, streets, buildings, building sensor models, to physics calculations, and more. It is like a creator, constructing the whole world, and updating the world according to the client’s foreign instructions. It itself is based on 3D rendering made by UnrealEnigne.
- Client: If the server constructs the entire world, the client controls the world operates at different times. The user sends instructions to the server to guide the changes in the world by writing Python scripts (the latest version of C++ is also available), and the server executes according to the user’s instructions. In addition, the client side can also receive information from the server side, such as a road image captured by a camera.
CARLA Key Features:
- Traffic Manager: CARLA creates the Traffic Manager to simulate a traffic environment similar to the real world. Users can define different models, behavior models, and speeds of vehicles to interact with the Ego-Vehicle.
- Sensors: CARLA contains all kinds of sensor model simulating the real world, including cameras, Lidar, IMU, GNSS, and so on. The photos even have distortion and motion blur effects in order to mimic the effects in the real world. User can attach these sensors to different cars to collect various data.
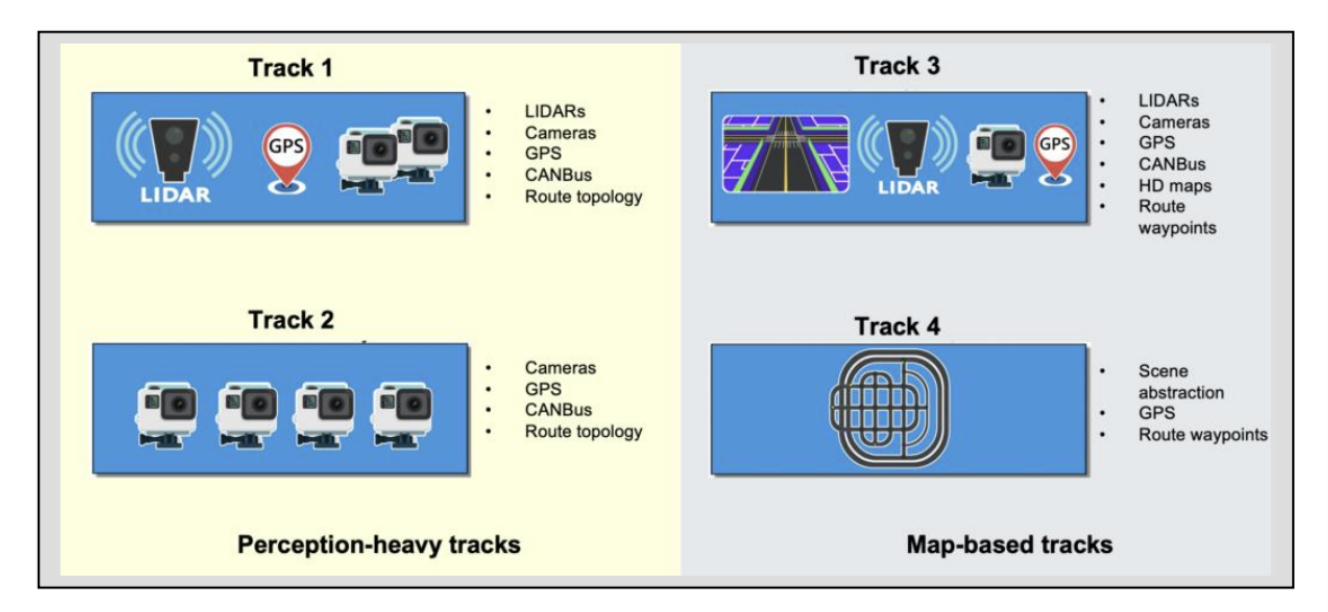
- Recorder: The recorder module is used to record the status of each step for the purpose of reviewing, reproducing.
- ROS bridge: CARLA can interact with ROS and Autoware. This module is important for testing the autopilot system in simulation.
- Open Assest: Developer can add a customized object library to the simulation world with this module. For example, we can add a cool flying car to the default vehicle blueprint and the Client module can use it.
Python API Reference
1st- World and client: The world is an object representing the simulation. It acts as an abstract layer containing the main methods to spawn actors, change the weather, get the current state of the world, etc. The client is the module the user runs to ask for information or changes in the simulation. A client runs with an IP and a specific port. It communicates with the server via terminal.
2nd- Actors and blueprints: An actor is anything that plays a role in the simulation such as vehicles. Blueprints are already-made actor layouts necessary to spawn an actor.
3rd- Maps and navigation: The map is the object representing the simulated world, there are eight maps available. Traffic signs and traffic lights are accessible as carla.Landmark objects that contain information about their OpenDRIVE definition.
4th- Sensors and data: Sensors wait for some event to happen, and then gather data from the simulation. A sensor is an actor attached to a parent vehicle.
Here’s the interface in CARLA we can see after we render the environment:
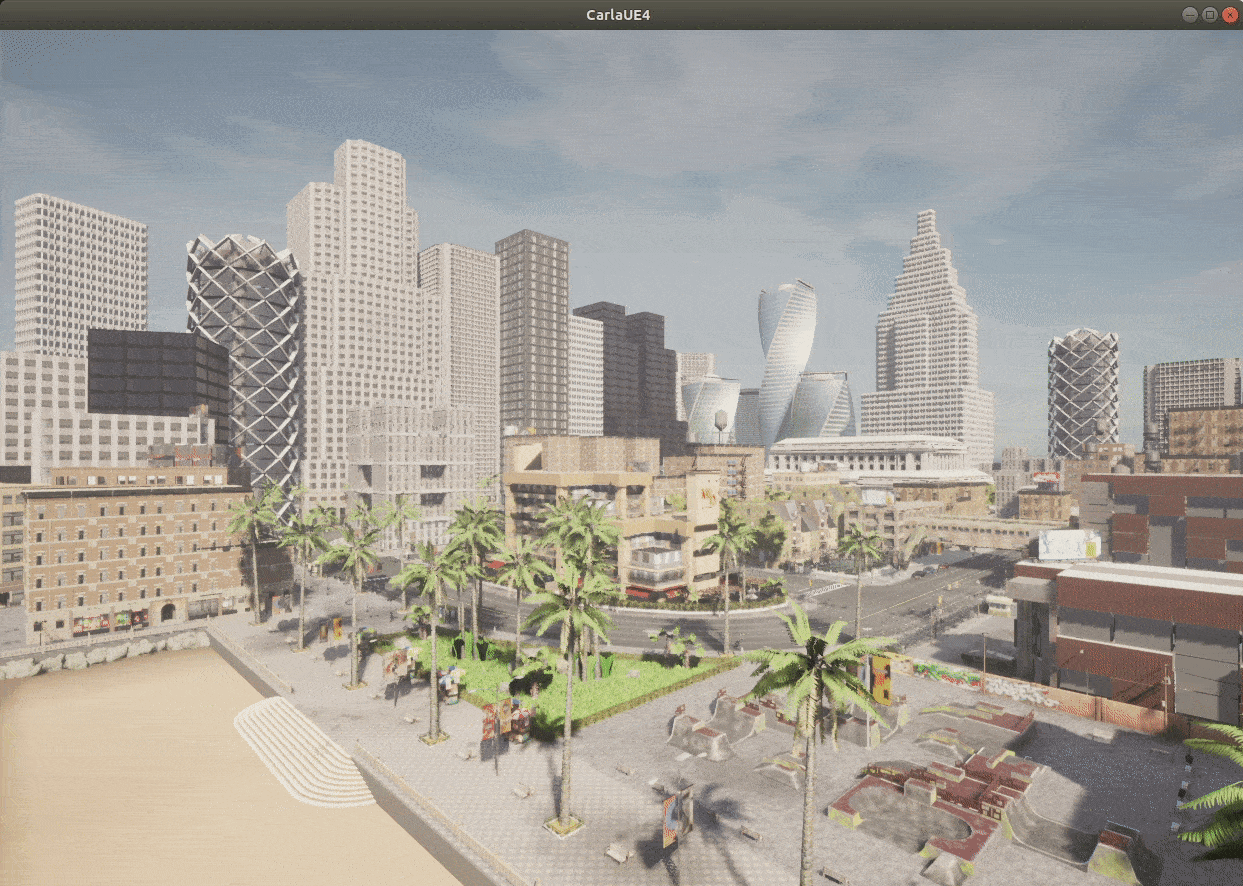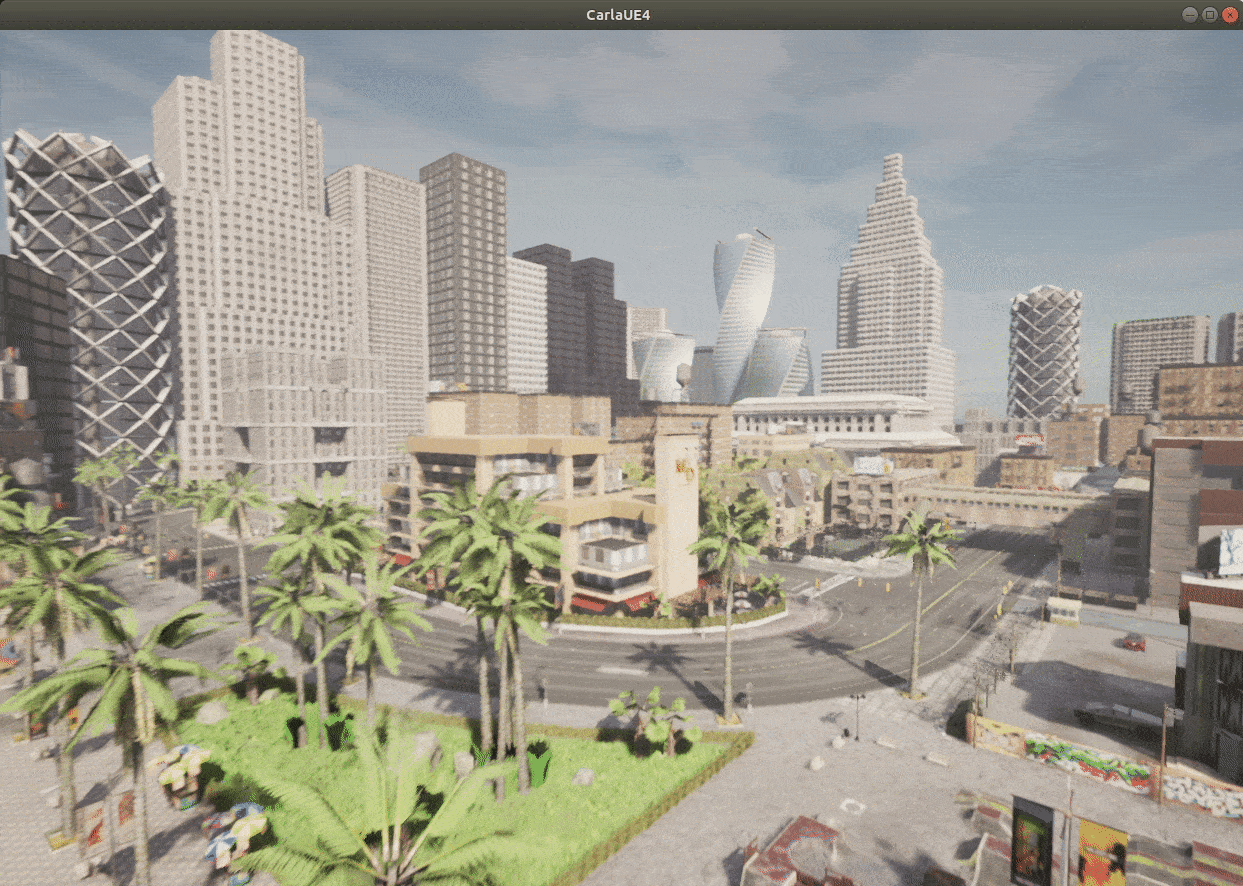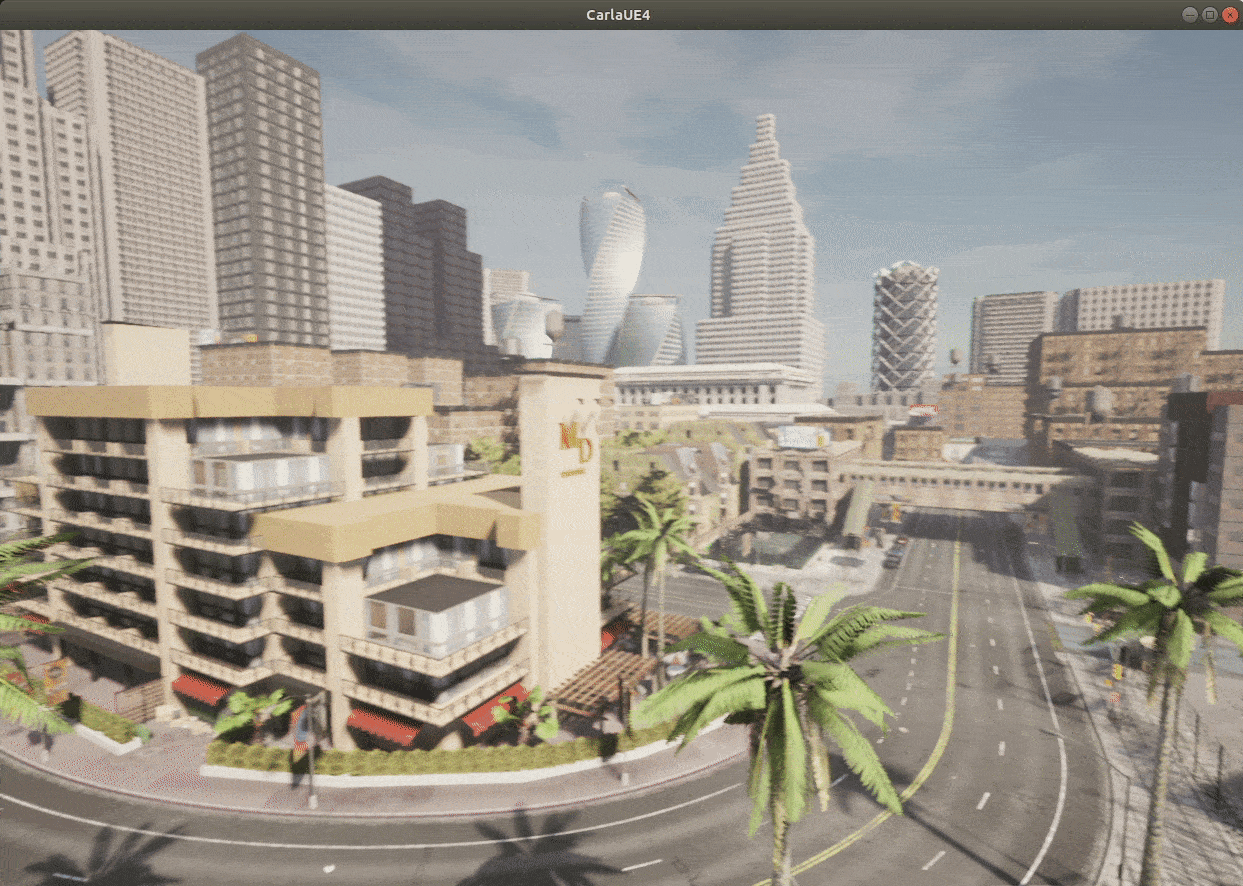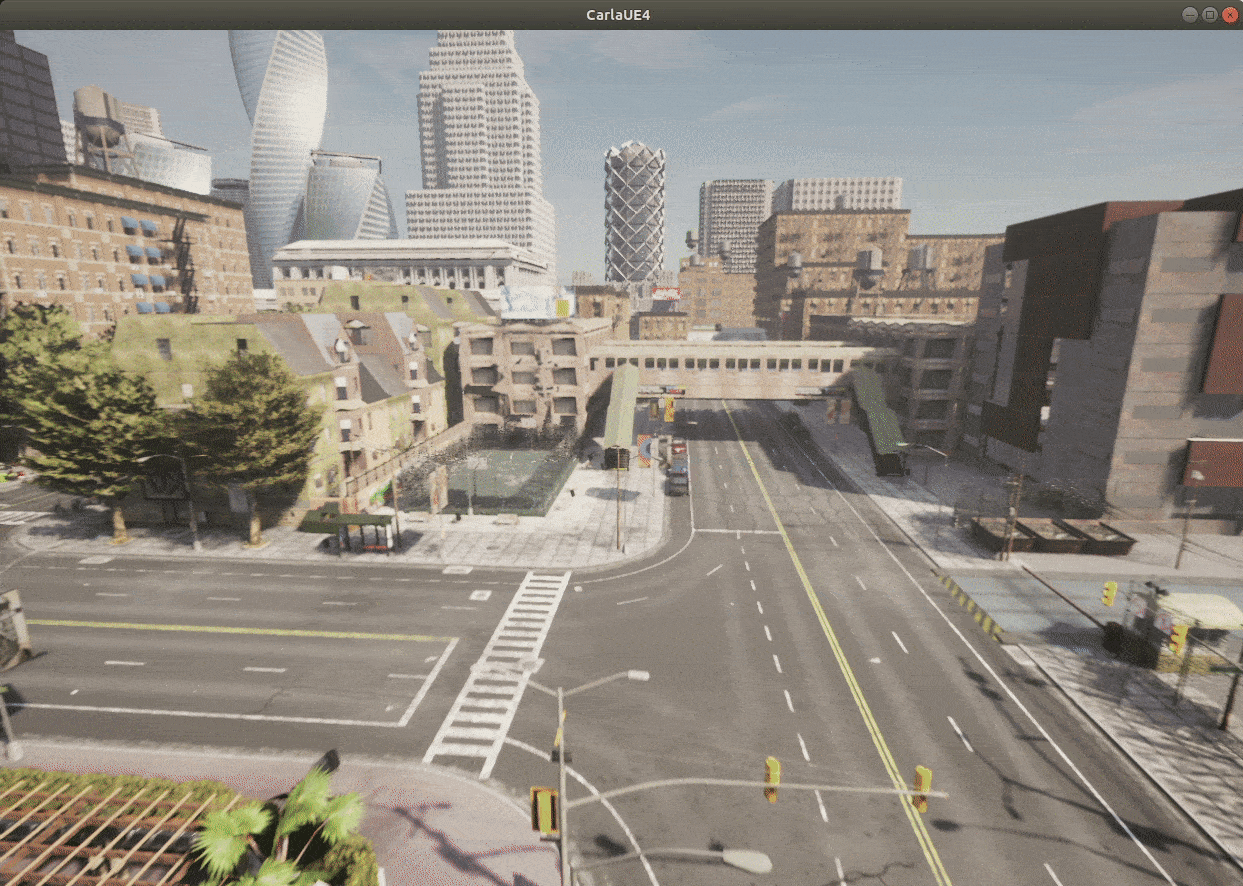
Toolkits and Libraries
- Python 3.7
- Demo Video for CARLA Simulator 0.9.13:
Current Progress
1. Construct Environment
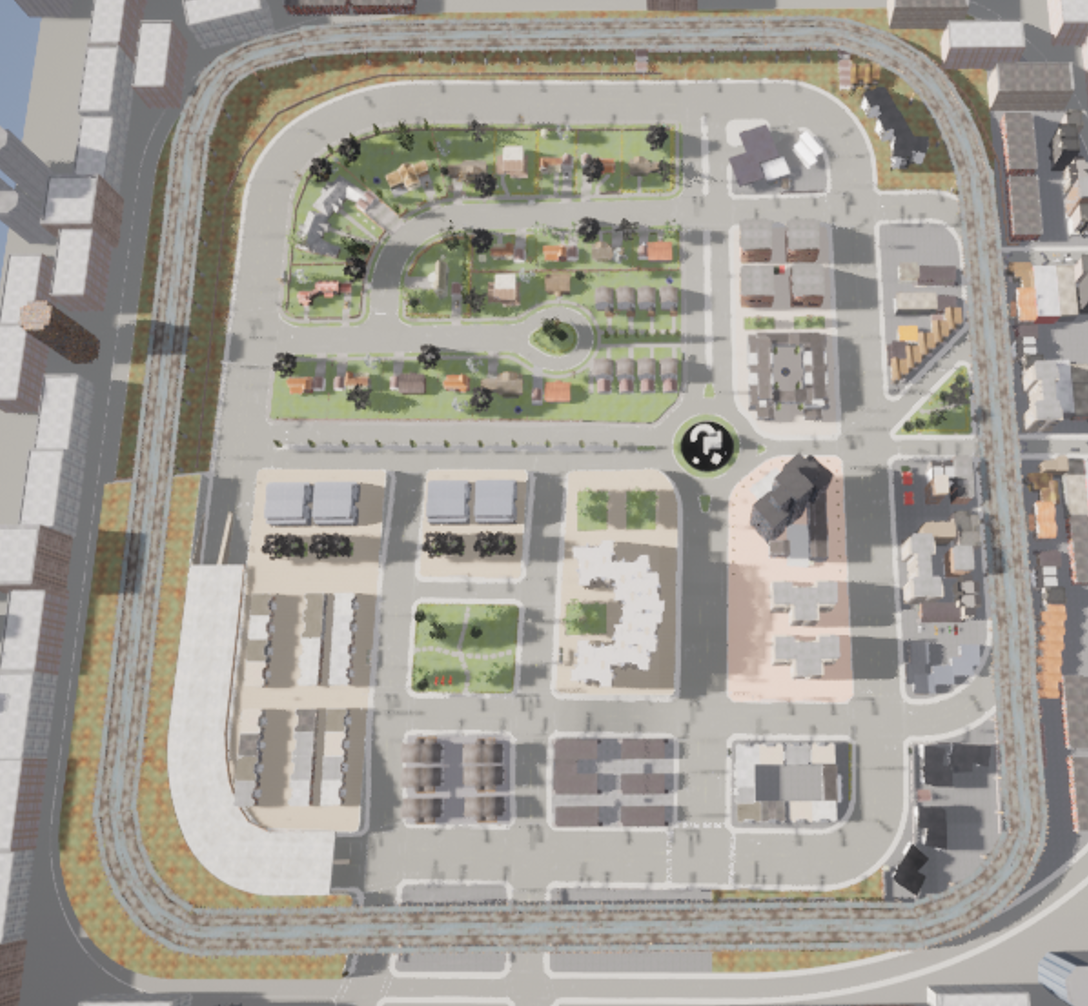
CARLA provides many different maps, here we choose Town3 as our training map (shown as below). We tried to tune those important hyperparameters to meet the best training performance. For parameter actions, we found that if we set too many actors, the computer will freeze severely, but if we set few actors, the training effect will not be very obvious. So finally we set actors as 50 vehicles and 0 walkers to maintain a great working balance. In addition, the speed of our agent was set about 15m/s. We did not set the weather parameter. Under these setting, we can successfully train an agent to reach the destination without collisions.
2. Q-learning Fomula
First, we try to build a simple Q-learning model on CARLA to test our car.
Q-learning is a model free reinforcement learning algorithm. It is an off policy algorithm and contains an exploratory policy to interact with the environment, then let the learning policy learn from the experience.
The core of off policy Q-learning is off-policy learning of action values Q(s,a) and no importance sampling. We will apply the TD method, let the next action in TD target is selected from the alternative action and then update Q(s,a) towards value of alternative action. First, we allow both behavior and target policies to improve. The target policy π is greedy on Q(s, a). Besides, the behavior policy μ could be totally random, but we let it improve following ϵ-greedy on Q(s, a).

Advantage:
- Learn about optimal policy while following exploratory policy.
- Learn from observing humans or other agents.
- Re-use experience generated from old polices.
3. About State
Total 4 Part: birdeye, lidar, camera, car state.
- Variables in car state:
- lateral distance to lane markings
- angle to lane markings
- current speed
- distance to the vehicle ahead
For the Q-learning model, we choose lateral distance to lane markings as the variable for car state. The variable is a continuous variable. For the purpose to building a simple Q-learning model, we transform the state from continuous variable to discrete variable.
- So there are total 9 different states including:
- distance <= -3
- -3 < distance <= -2
- -2 < distance <= -1
- -1 < distance <= -0.5
- -0.5 < distance <= 0.5
- 0.5 < distance <=1
- 1 < distance <= 2
- 2 < distance <= 3
- distance > 3
4. About Action
Two Actions: acceleration, steer.
- For steer: Steer is the angle of wheel turning. Default value [-1, 1]. We did not choose default value, because the maximum angle is around 70 degree and we do not want the angle to be too large.
- Acceleration and steer all have the case for continuous variables and discrete variables. So we choose 2 discrete variables for our Q-learning model (‘discreteAcc’: [-2.0 0.0, 2.0], ‘discreteSteer’: [-0.1, 0.0, 0.1], negative numbers are turning right, positive numbers are turning left). Finally, we form 9 different actions by combining these two variables.

5. Other hyperparameters
-
discount: set to 0.9
-
epsilon: first set to 0.8, then slightly lower down the value, finally set to 0.5
-
episode: set to 10000
6. Testing
Each time the current reward, state distant and action will be output. At the same time, the agent can be observed with pygame. In pygame, we can see the trajectory, predicted route of the car, as well as its response on the left side. There is the visual map of sensors such as radar in the middle. And on the right side of the window, it shows the pictures of the virtual reality from a driver’s perspective. If the agent collides or deviates from the course during the training process, a new location will be randomly generated to start the test.
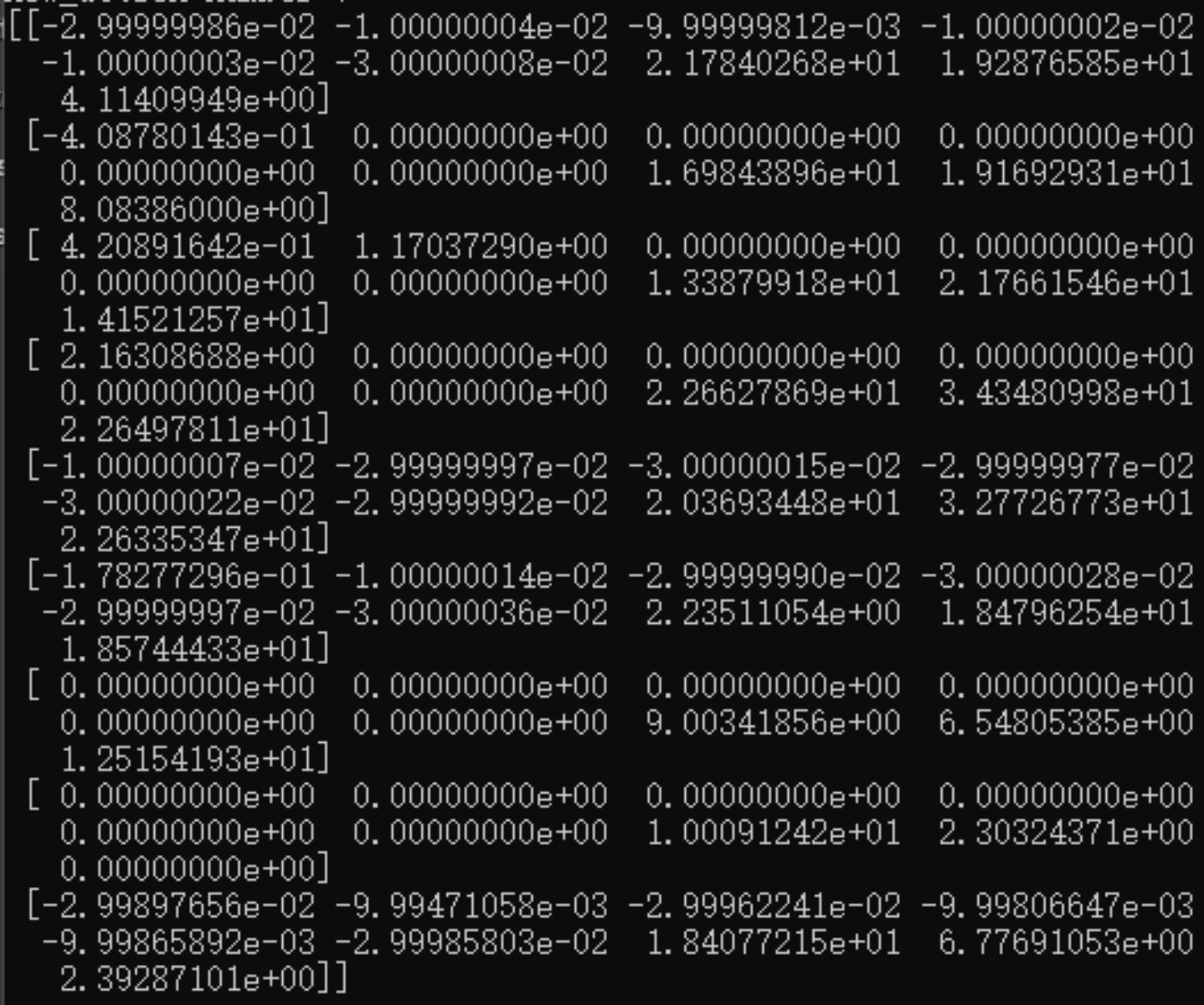
7. Q-table Performance
In the first training, we use np.zero to generate a q-table with all 0s. The picture shows our first q-table. In each training, we will output a q-table. We will store this q-table with np.save later, and use this q-table for a new training next time with np.load.
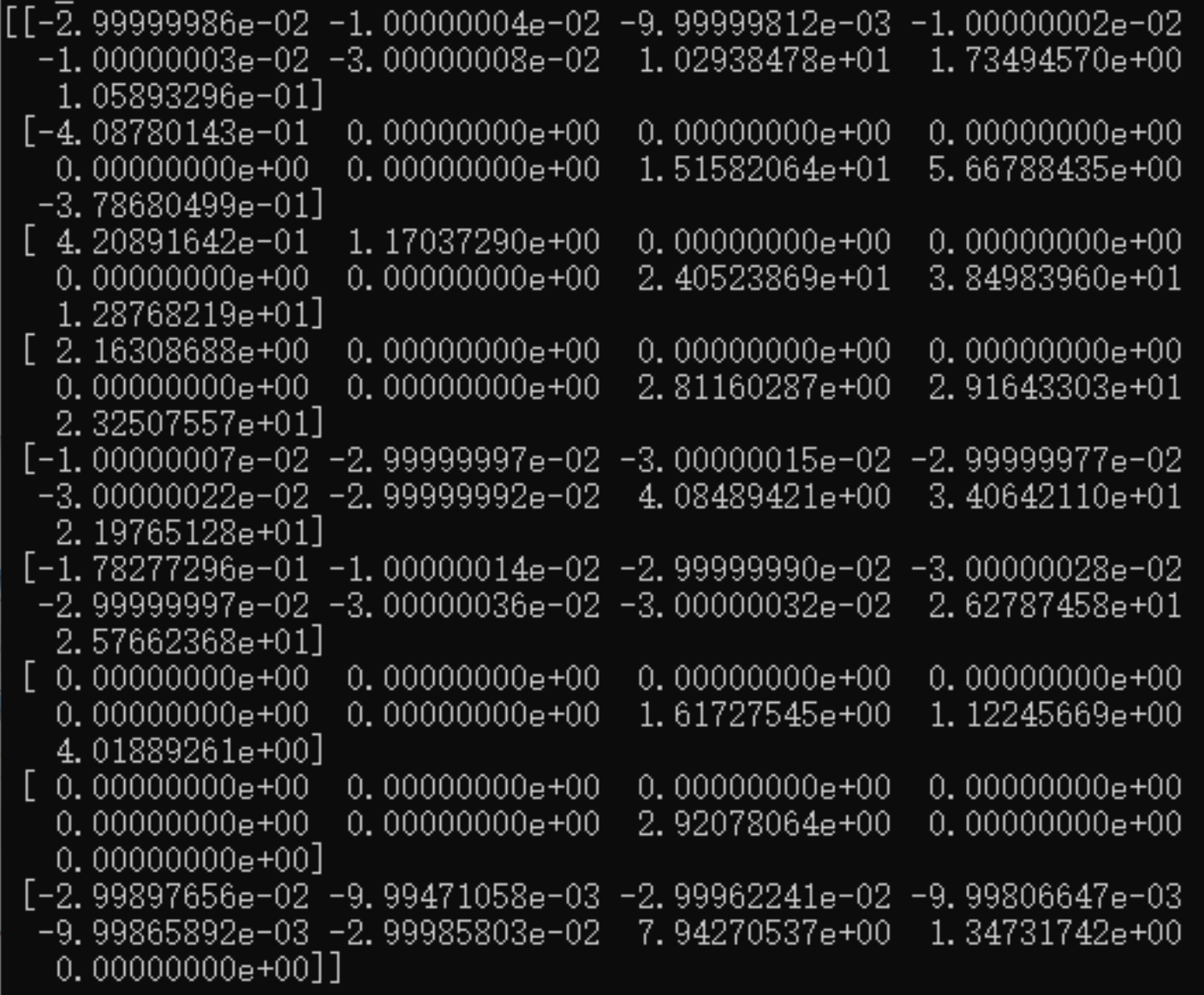
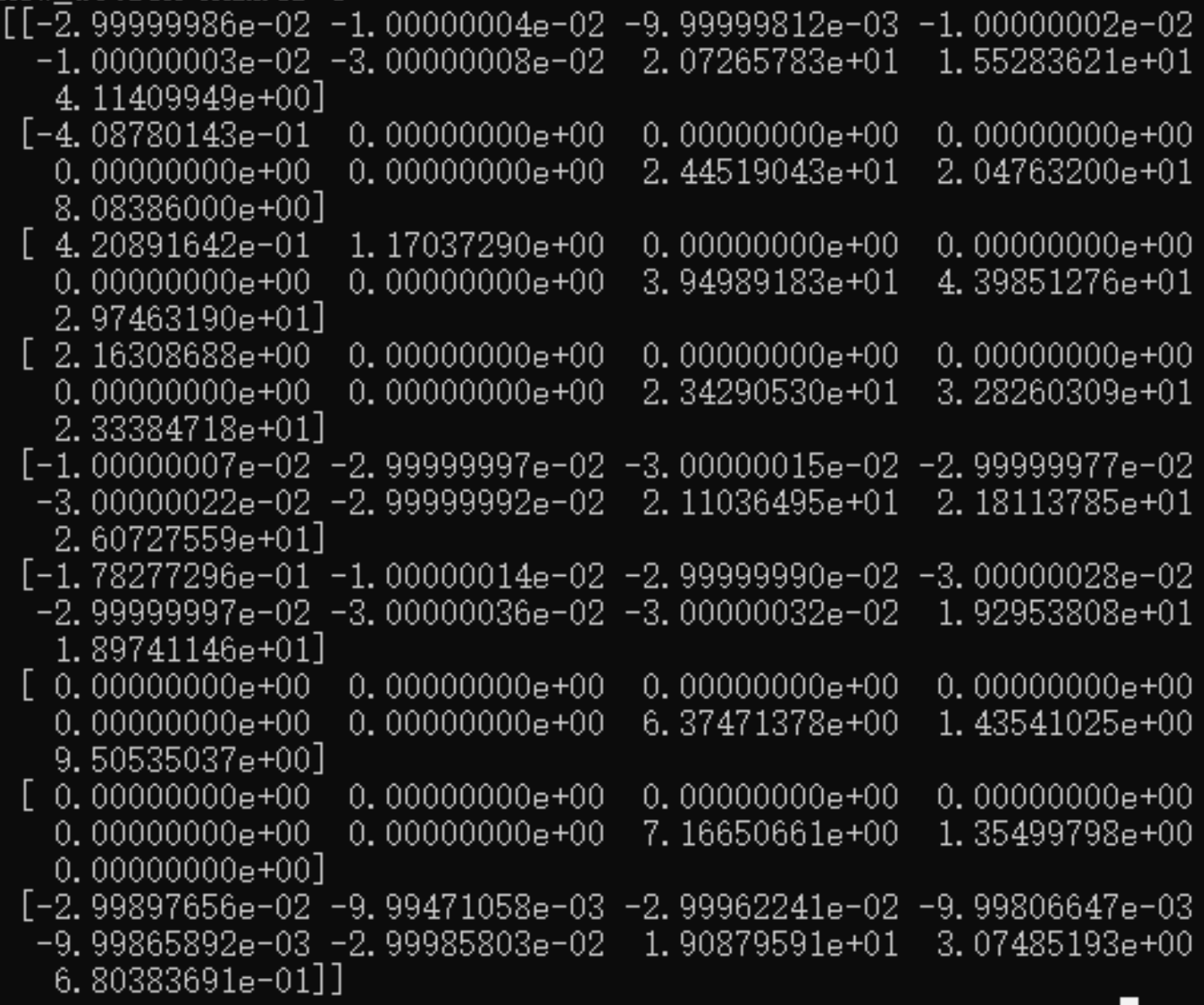
Conclusion
In the CARLA autonomous driving car project, we have a deeper understanding on the reinforcement learning and practice the skillset onto the real work. In the process, we learned how to render the CARLA environment and interact our Q-learning model with CARLA simulator and the built system. Besides, the training performances become better and better by tuning hyperparameters and testing in different environments with practice. As the number of episodes increases, the strategy will be better. Reward fluctuates a lot, but it is overall increasing. To conclude, the overall results were not very good due to the selection of the Q-learning model.
As the first time to use CARLA, we are very satisfied with this result. The main reason is that we are more familiar with the environment of CARLA. Besides, we implemented a simple Q-learning model and let the agent drive on the desired trajectory for a period of time through the environment constructed in the paper. Our future plans hope that we can build a better model on the basis of familiarity with CARLA.
Future Work
- Render a more complex environment on CARLA.
- For example, we can set up different bad weather on the testing.
- Or increase the pedestrians on the streets for blocking the street.
- Train more different tasks on the autonomous car.
- Like training a car to learn U-turn or reverse.
- Or training a car to track another car.
- Implement a simple DQN model.
- Deep Q-Learning manages two-dimensional arrays by introducing neural networks. It estimates the Q value during the learning process, where the state is the input to the network and the output is the Q value corresponding to each action.
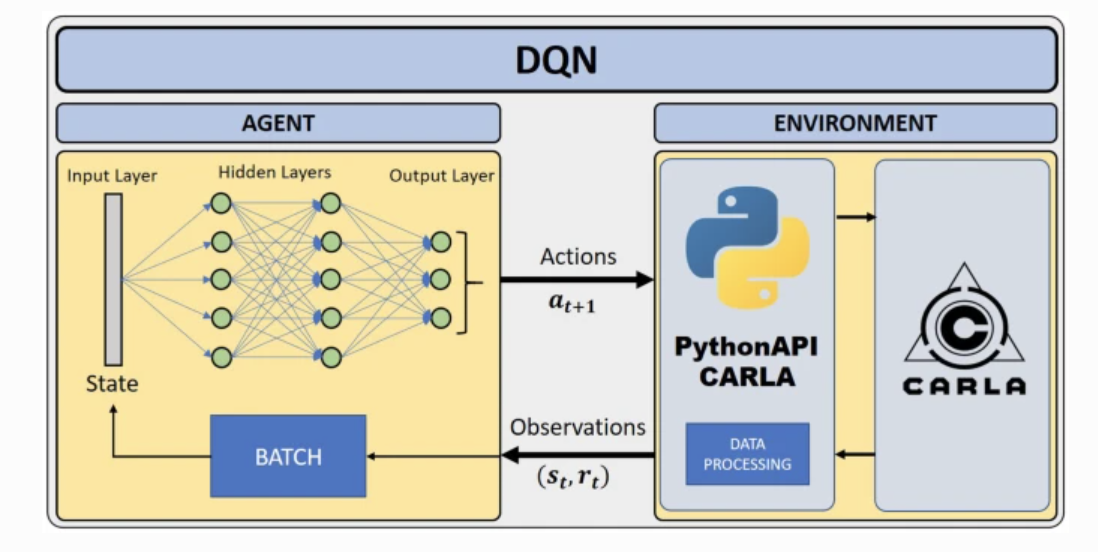
Fig 10. DQN-based Deep Reinforcement Learning architecture - Explore the DDPG model.
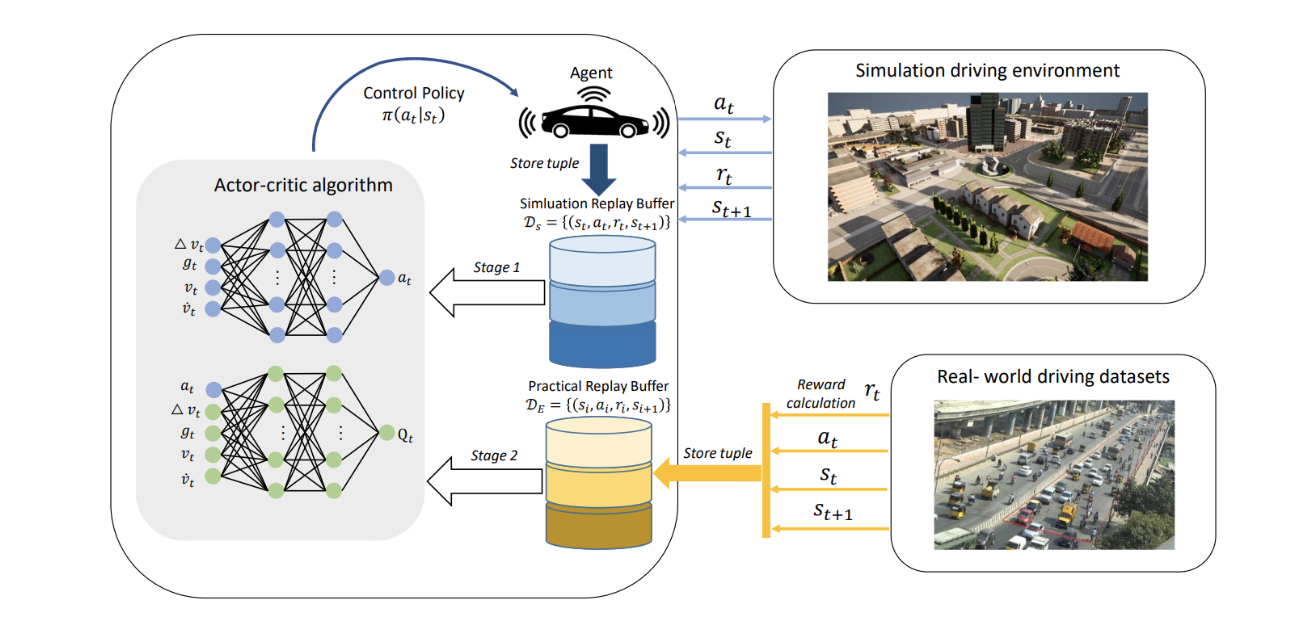
- DDPG algorithm can work well with continuous variables, so it is more suitable for autonomous driving tasks. It learns Q-functions and DRL algorithm at the same time. The model uses off-policy data and the Bellman equation to learn a Q-function, and the DDPG only learns the policy part from Q-function.
Project Timeline
- Week 3,4 - Confirmed the research topic, did research and read related paper.
- Week 5 - Brainstormed ideas, made a plan on the target model.
- Week 6 - Install CARLA
- Week 7 - Get familiar with the simulation environment.
- Week 8,9 - Built Q-learning model, did testing with different hyperparameters.
- Week 10,11 - Try DQN model, update and refine the report, make a video presentation.
Final Presentation Update
Team 18 Contact Info
Zuo Zhi
- UID: 305346349
- EMAIL: joannazz@g.ucla.edu
Yinglu Deng
- UID: 305496193
- EMAIL: ceciliadeng12@g.ucla.edu
Reference
[1] Akhloufi, M.A., Arola, S., Bonnet, A., 2019. Drones chasing drones: Reinforcement learning and deep search area proposal. Drones 3, 58.
[2] Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., Jackel, L.D., Monfort, M., Muller, U., Zhang, J., et al., 2016. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316 .
[3] Dworak, D., Ciepiela, F., Derbisz, J., Izzat, I., Komorkiewicz, M., Wojcik, M., 2019. Performance of lidar object detection deep learning architectures based on artificially generated point cloud data from carla simulator, in: 2019 24th International Conference on Methods and Models in Automation and Robotics(MMAR), IEEE. pp. 600–605.
[4] Gomez-Hu elamo, C., Del Egido, J., Bergasa, L.M., Barea, R., L opez-Guill en, E., Arango, F., Araluce, J., Lopez, J., 2020. Train here, drive there: Simulating real-world use cases with fully-autonomous driving architecture in carla simulator, in: Workshop of Physical Agents, Springer. pp. 44–59.
[5] He, Y., Zhao, N., Yin, H., 2017. Integrated networking, caching, and computing for connected vehicles: A deep reinforcement learning approach. IEEE Transactions on Vehicular Technology 67, 44–55.
[6] Isele, D., Rahimi, R., Cosgun, A., Subramanian, K., Fujimura, K., 2018. Navigating occluded intersections with autonomous vehicles using deep reinforcement learning, in: 2018 IEEE International Conference on Robotics and Automation (ICRA), IEEE. pp. 2034–2039.
[7] Liu, H., Huang, Z., Lv, C., 2021. Improved deep reinforcement learning with expert demonstrations for urban autonomous driving. arXiv preprint arXiv:2102.09243.
[8] MAURER. (2016). Autonomous Driving. Technical, Legal and Social Aspects. 10.1007/978-3-662-48847-8.
[9] Niranjan, D., VinayKarthik, B., et al., 2021. Deep learning based object detection model for autonomous driving research using carla simulator, in: 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), IEEE. pp. 1251–1258.
[10] ROHMER, E. (2013) “V-REP: A versatile and scalable robot simulation framework,” 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, 2013, pp. 1321-1326.
[11] Treiber, M., Kesting, A., 2017. The intelligent driver model with stochasticitynew insights into traffic flow oscillations. Transportation research procedia 23, 174–187.